Durante más de cincuenta años, el software empresarial tuvo una función clara: registrar lo que había pasado. El ERP capturaba transacciones, el CRM guardaba interacciones, el SCM trazaba movimientos. Los sistemas eran, en esencia, archivos muy inteligentes con mucha lógica de negocio dentro, pero archivos al fin y al cabo.
Después de leer este artículo posiblemente tampoco, paso a paso se hace el camino
La Empresa Autónoma no es una nueva funcionalidad encima de ese modelo, es la ruptura de ese modelo. SAP está cambiando el contrato fundamental con sus clientes: de registrar lo que ocurre a ejecutar lo que tiene que ocurrir a continuación. Es un cambio filosófico, y conviene entenderlo como tal antes de entrar en los detalles de implementación.
Esto fué presentado como algo disruptivo y, para mi, muy relevante en el SAPPhire de este 2026, ya lo conté aquí:
El problema que viene a resolver
Hay una brecha estructural en casi todas las organizaciones que usan software empresarial, y no es un problema de personas ni de tecnología aislada. Los sistemas saben lo que está pasando, los equipos también lo saben, pero entre el momento en que el sistema registra una señal y el momento en que alguien actúa sobre ella, el valor se escapa.
Supply Chain detecta la disrupción antes de que llegue, pero el proceso de tomar una decisión y ejecutar una alternativa lleva días. Finance tiene la señal de liquidez, pero la coordinación entre departamentos para actuar consume semanas. El responsable de servicio ve la cola de tickets escalar, pero las reglas de enrutamiento estáticas siguen mandando trabajo al equipo equivocado.

SAP lo llama «el impuesto de la empresa fragmentada»: el coste silencioso de que tus mejores personas pasen la mayor parte del tiempo gestionando el espacio entre funciones en lugar de mover el negocio hacia adelante. No es un problema de rendimiento individual. Es un problema de arquitectura.
El software tradicional reacciona / La Empresa Autónoma actúa.
Qué es exactamente
La Empresa Autónoma (Autonomous Enterprise) es el siguiente modelo operativo para la era de la IA, donde las personas fijan la dirección y la IA ejecuta. No es un producto, no es una versión nueva de nada, es una forma diferente de operar.
Esto importa porque cambia lo que se le pide al CIO. No se le pide que compre un software nuevo, se le pide que cambie el contrato de trabajo entre sus sistemas y sus equipos. Los sistemas dejan de ser herramientas que las personas usan para hacer cosas, y pasan a ser sistemas que actúan mientras las personas supervisan, corrigen y fijan prioridades.
Es el movimiento de operador a supervisor. Y tiene implicaciones profundas en cómo se diseña la organización, cómo se miden los resultados y cómo se gobierna el riesgo.
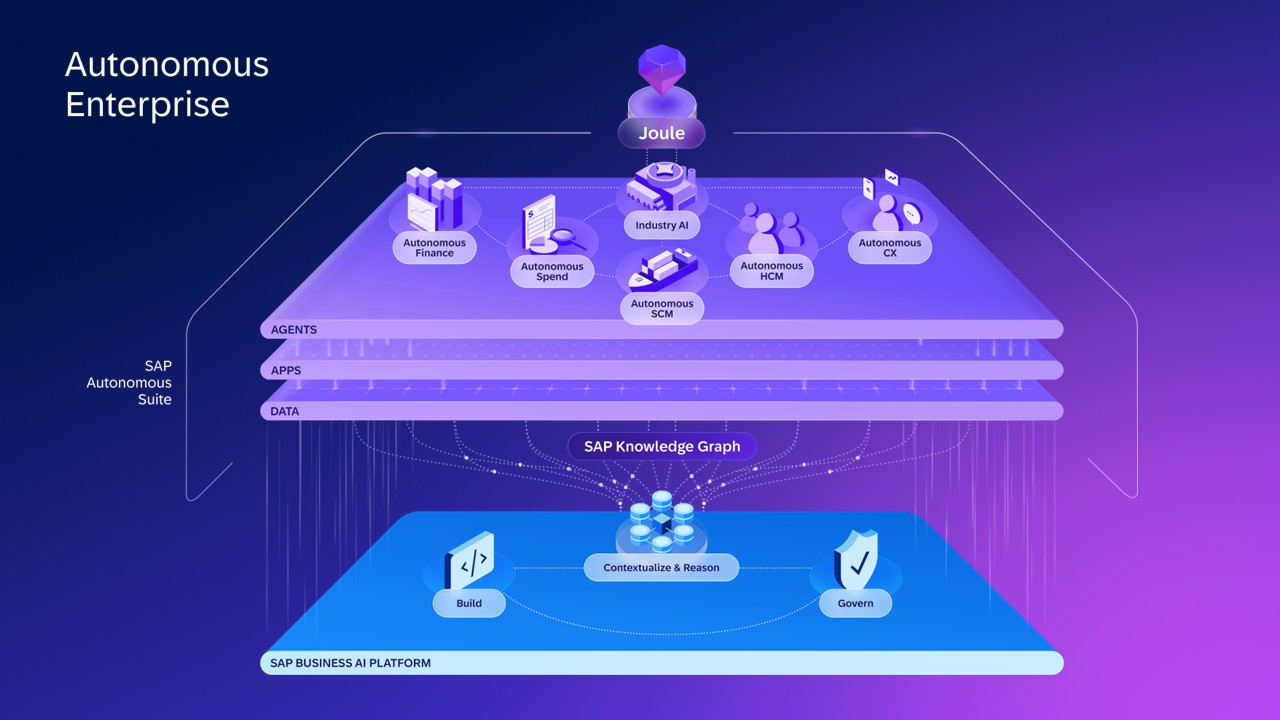
Los cinco dominios autónomos
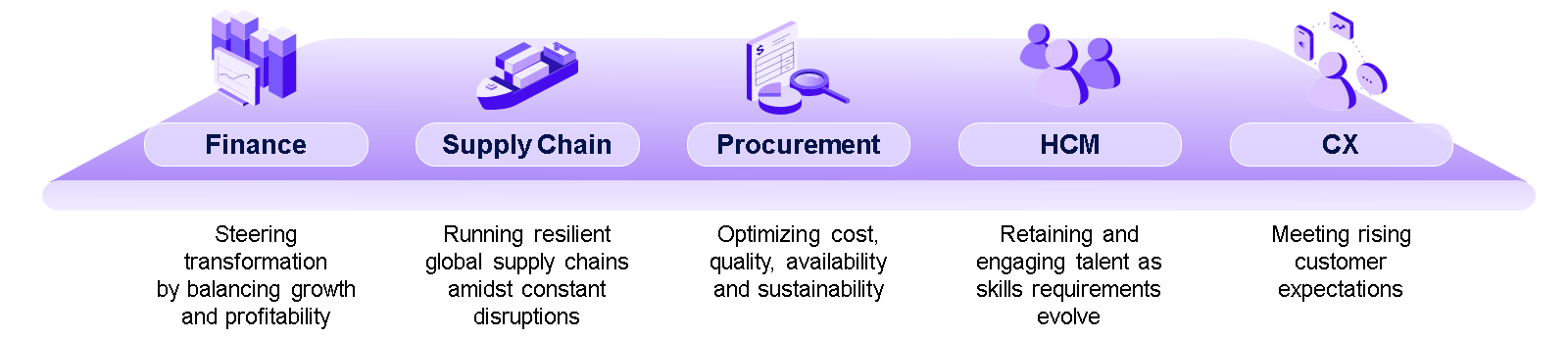
El núcleo operativo de la Empresa Autónoma son cinco dominios: Finance, Spend (compras y procurement), Supply Chain, HCM y Customer Experience. Cada uno tiene su propio conjunto de agentes que ejecutan procesos de extremo a extremo dentro de esa función.
Lo que hace esto arquitectónicamente relevante es que los cinco dominios no son módulos independientes conectados por integraciones, son un sistema. Una decisión en Finance aparece en Supply Chain sin integración adicional. Una señal en CX impacta en Spend sin que nadie tenga que mapear campos entre sistemas.
El ciclo dentro de cada dominio es continuo: las personas fijan dirección, las aplicaciones generan señales, los datos proveen contexto y los agentes actúan.
El «impuesto de integración» (ese coste oculto de conectar sistemas que no fueron diseñados para hablar entre sí) desaparece porque la suite nació integrada.
Un cambio de paradigma, no de versión
SAP lleva años haciendo evoluciones de producto, esto es diferente. No es una versión nueva de un módulo ni una funcionalidad añadida a una pantalla existente. Es un cambio en la premisa fundamental del software empresarial:
Del sistema que Recuerda al sistema que Actúa.
Los cambios de paradigma suelen verse con más claridad desde fuera que desde dentro. Cuando estás en la trinchera de un proyecto de migración o de una implantación en curso, el día a día consume la perspectiva larga. Pero vale la pena entender qué está construyendo SAP, porque el destino al que apunta cambia las preguntas que hay que hacerse en cada proyecto que empiece hoy.
La brecha entre saber y hacer ha sido el coste invisible de la empresa moderna durante décadas. La Empresa Autónoma es la propuesta de SAP para cerrarla.
Mi opinión
Dicho todo esto, me permito una nota de cautela.
La industria tecnológica tiene un patrón conocido. IoT iba a conectar todo y optimizar cada proceso industrial, Blockchain iba a eliminar intermediarios y rediseñar la cadena de suministro, y ambos conceptos coparon portadas, conferencias y presupuestos durante años. Hoy apenas se mencionan, no porque la tecnología fuera falsa, sino porque el hype superó con creces la velocidad real de adopción y las expectativas no encontraron el aterrizaje que prometían.
SAP tiene su propio historial en esta línea. Leonardo se anunció como la plataforma que llevaría IoT, Machine Learning y Blockchain al mundo empresarial, y acabó absorbida por BTP sin demasiado ruido. SAP C/4HANA se presentó como el rival directo de Salesforce en CX, con cuatro nubes perfectamente integradas, y la integración tardó años en ser lo que el anuncio decía.
¿Es la Empresa Autónoma otro concepto destinado a desvanecerse? Yo creo que no, y tengo razones para pensarlo. La arquitectura que hay detrás no es un nombre sobre tecnología de terceros ni una visión sin producto: Joule existe, BTP existe, el Knowledge Graph existe. Hay una coherencia interna que Leonardo y C/4HANA no tenían en el momento de su anuncio. Además la revolución de esta tecnología la estamos viviendo a nivel personal y sabemos que existe, otra cosa es que pueda escalar con seguridad, estabilidad y coherencia al mundo corporativo.
Pero el hype existe, y es legítimo nombrarlo. Entre la arquitectura y la ejecución hay un trecho, y ese trecho lo recorren los clientes con sus proyectos, su deuda técnica y sus equipos. Lo que hay que vigilar en los próximos dos o tres años no es si SAP cumple el anuncio, sino si el mercado tiene la madurez para adoptarlo al ritmo que la propuesta exige.
