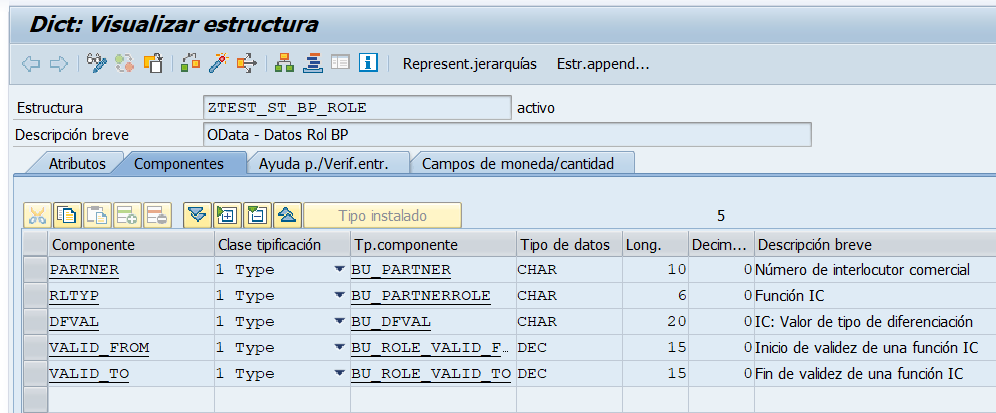
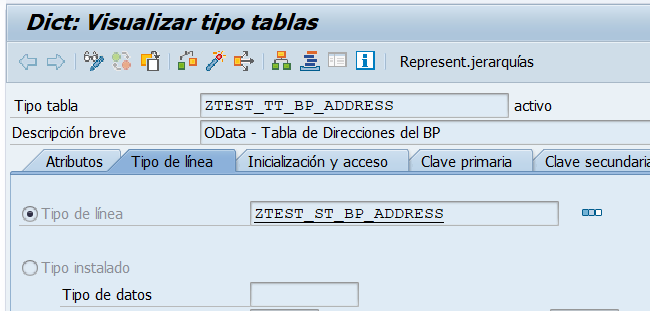
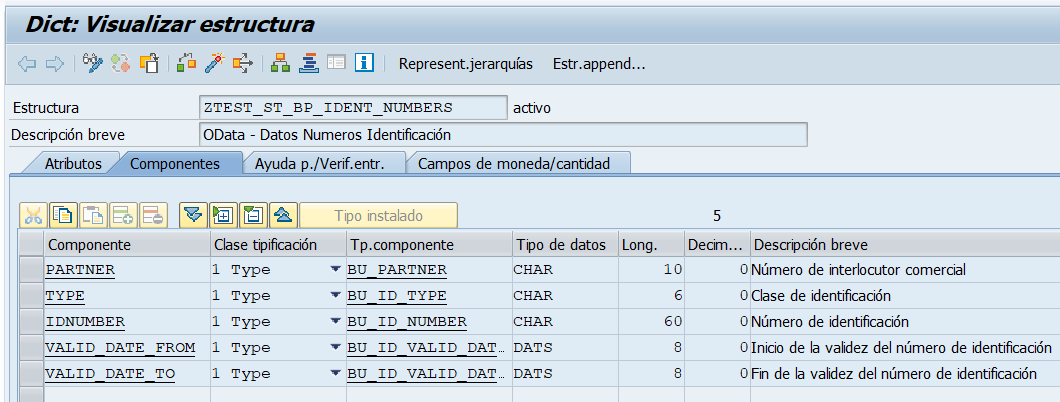
Vamos a hacer un parón en el camino, entenderéis porqué, en el estudio de cómo manejar servicios web OData en SAP con SAP Gateway. Lo que vamos a implementar es una herramienta de documentación y pruebas muy potente para nuestros servicios OData en nuestro sistema SAP. Se trata de implementar la funcionalidad de OpenAPI (el antiguo Swagger) en nuestro SAP para que genere el aplicativo de documentación y pruebas.
Serie de Artículos sobre OData
Este artículo pertenece a una serie de artículos que se van complementando poco a poco como itinerario de conocimiento:
- OData y SAP Gateway
- OData y SAP Gateway – II – Publicar un servicio OData en SAP
- OData y SAP Gateway – III – Recuperar Subentidades
- OData y SAP Gateway – IV – Opciones sobre Entidades y Campos
- OData y SAP Gateway – V – Documentar y Probar con OpenAPI (Swagger) (Este artículo)
¿Qué es OpenAPI?
OpenAPI es una especificación que define un estándar para construir y describir interfaces de programación de aplicaciones (APIs). OpenAPI es una evolución del formato conocido anteriormente como «Swagger», aunque a veces ambos términos se usan indistintamente. Es ampliamente utilizado para APIs RESTful y permite a los desarrolladores y sistemas documentar y entender cómo interactuar con una API sin necesidad de ver su implementación interna.

Algunos puntos clave de OpenAPI:
- Estandarización: Define un formato estandarizado para describir los endpoints de una API, incluyendo los métodos HTTP disponibles (GET, POST, PUT, DELETE, etc.), los parámetros de entrada, respuestas y errores que puede generar.
- Documentación automática: Una de las características más útiles es que permite generar documentación automáticamente a partir de la descripción de la API, lo cual facilita su uso por otros desarrolladores. Este es el motivo principal de este artículo sobre la serie de OData.
- Interacción simplificada: Con OpenAPI, las herramientas y bibliotecas pueden generar clientes o servidores automáticamente en diversos lenguajes de programación, facilitando el desarrollo de aplicaciones que consumen o exponen APIs.
- Archivo descriptor: Usualmente, la especificación OpenAPI se escribe en un archivo YAML o JSON, que describe toda la estructura de la API.
Como he comentado anteriormente, este artículo se llama «Documentar y Probar con OpenAPI» porque es extremadamente útil usar OpenAPI para documentar y tener un entorno de pruebas sólido y robusto. Y, dentro de nuestro estudio de OData, nos va a venir muy bien esta herramienta para entender como funciona y en que afecta la configuración del Proyecto Gateway.
Proyecto OpenAPI para SAP en GitHub
Existe un proyecto OpenAPI para SAP open source en GitHub para poder ser importado y usado en los sistemas SAP. El proyecto, de Geert Janklaps es el siguiente geert-janklaps / abap-openapi-ui y lo explica en este artículo de SAP Community ABAP OpenAPI UI v1 released!.
Pero ¿Cómo importamos ese proyecto en nuestro sistema SAP? Pues como vimos en la entrada:
Tenemos la herramienta abapGit para poder manejar los repositorios Git como GitHub en SAP, por lo que el primer paso es instalar la versión standalone de AbapGit. Hago esto porque en principio lo único que quiero es poder importar el proyecto OpenAPI. Si quisiese usar un repositorio Git para trabajar con versionado y todo lo que ofrece instalaría la «Developer version».

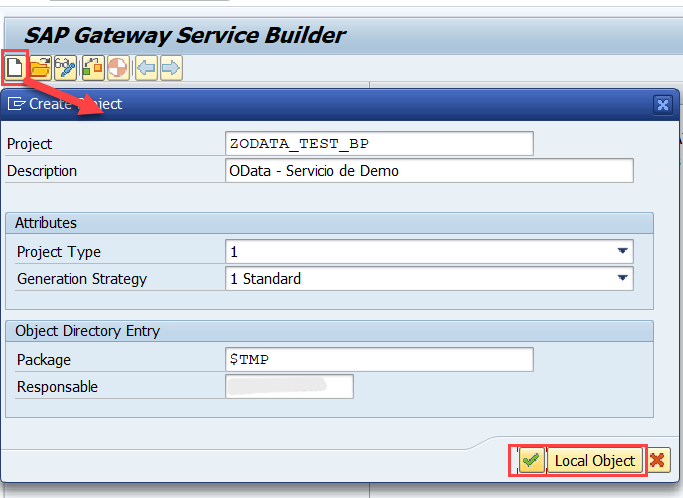
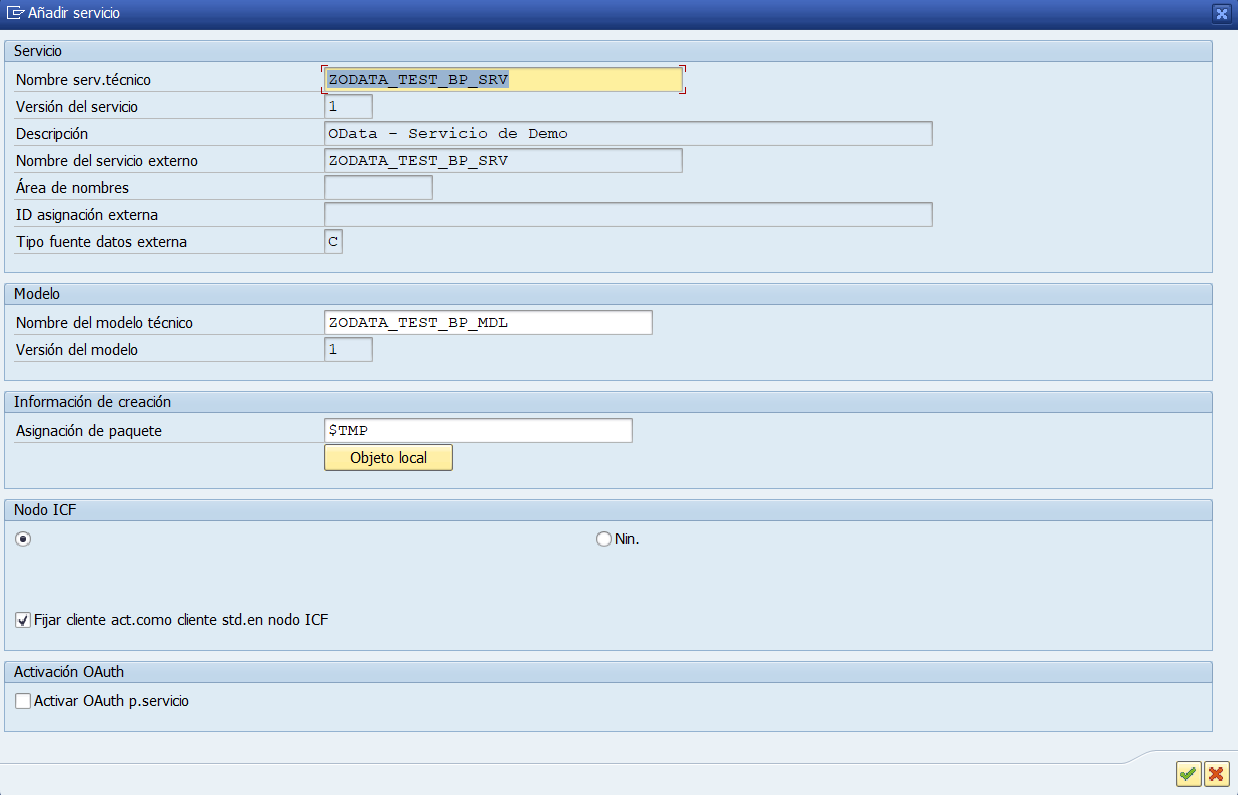
Por lo tanto creamos el report ZABAPGIT_STANDALONE en nuestro sistema, como yo solo lo quiero para importar proyectos de ABAP en Git lo crearé como objeto local, porque no necesito transportarlo. Una vez hayamos importado el código tendremos el siguiente report:

Instalar el proyecto ABAP OpenAPI
Una vez tenemos el report de ABAPGit y sabemos donde está el proyecto podemos instalarlo, para ello lo primero que hacemos es crear un repositorio Offline pulsando el botón superior New Offline.

Y como resultado nos habrá creado el repositorio Offline.

Ahora es cuando vamos a importar, en este repositorio, el proyecto ABAP OpenAPI que s el siguiente geert-janklaps / abap-openapi-ui y descargamos el proyecto en ZIP

Y con este ZIP pulsamos el botón ImportZIP del repositorio que hemos creado anteriormente.

Y al importar nos dará un resumen de todos los objetos que va a crear en el repositorio en base al proyecto ABAP OpenAPI.

Si nos parece correcto, pulsaremos el botón Pull para aceptar la creación de los objetos.

Una vez aceptado, nos pedirá orden de transporte y generará los objetos del proyecto.
Transacción ZGW_OPENAPI
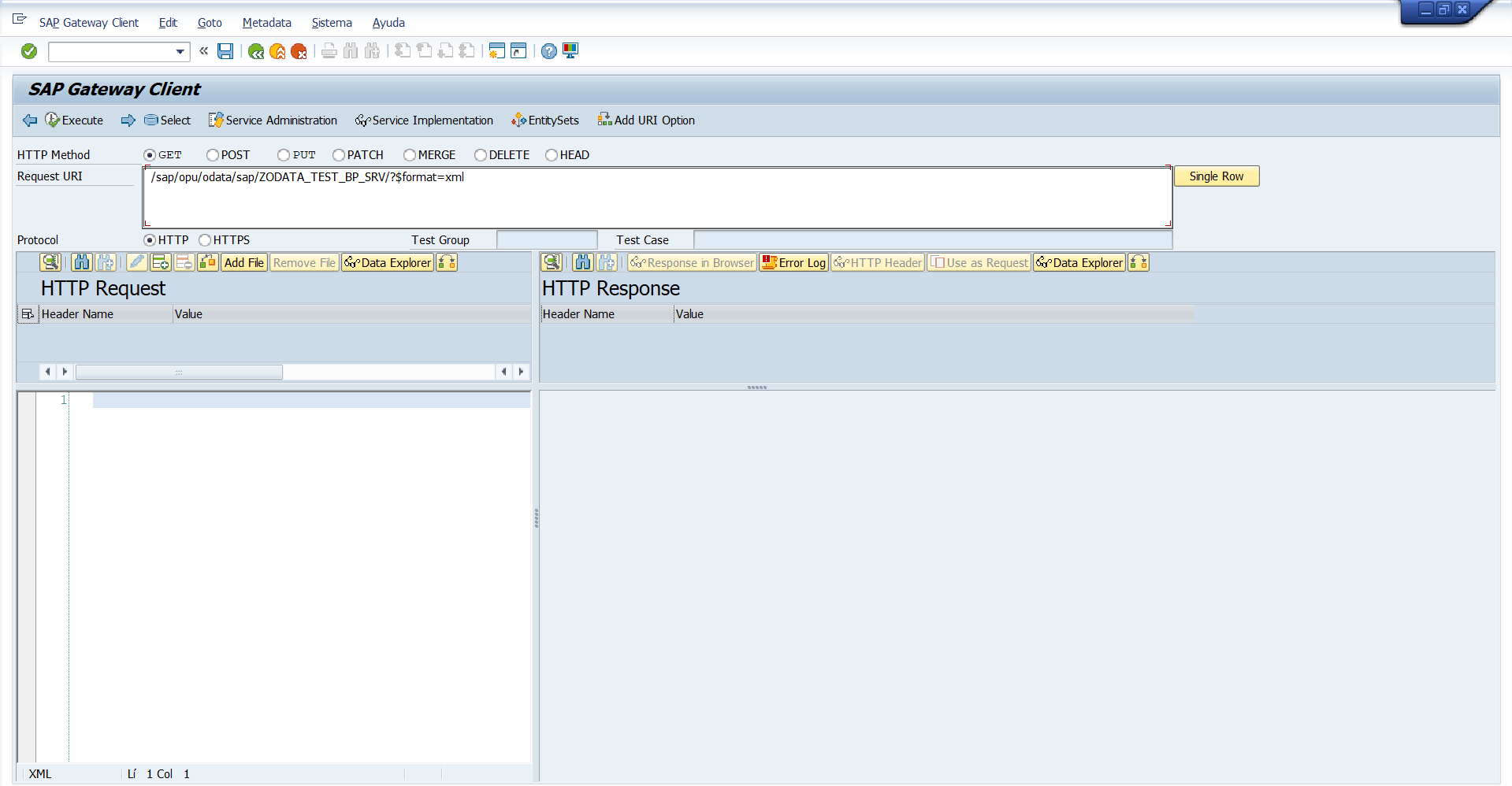
Si accedemos a la transacción ZGW_OPENAPI accederemos a esta pantalla:

Donde poder indicar nuestro Servicio OData y que nos genere la vista Swagger UI o JSON y, si seleccionamos Swagger UI nos saldrá una aplicación web OpenAPI con la definición de nuestro servicio, acciones posibles, campos y la posibilidad de probarlo.
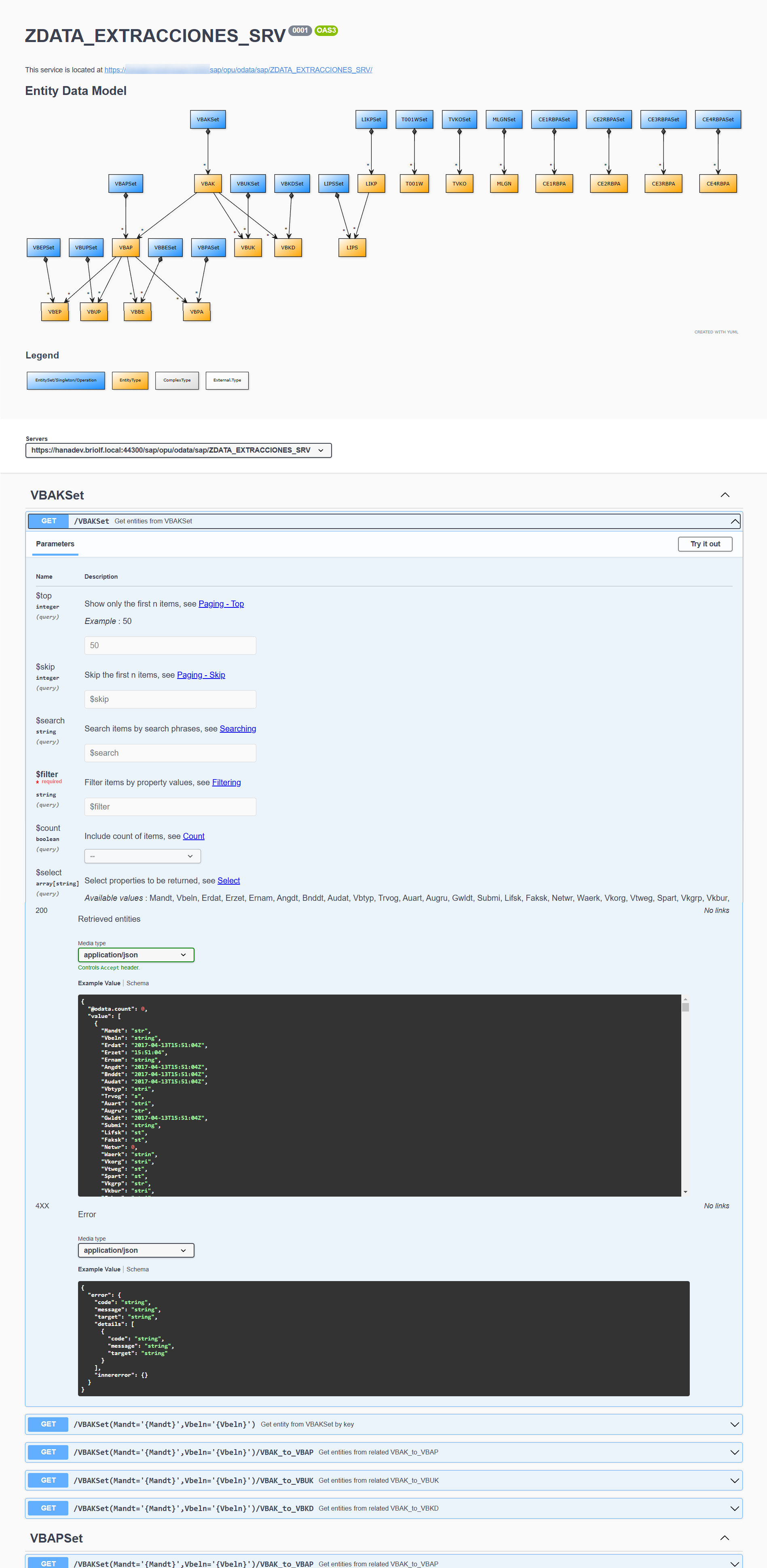
Para los que conocen el antiguo Swagger (ahora OpenAPI) ya sabrán las funcionalidades que ofrece. Pero para todos, de cara a los proyectos OData de SAP Gateway.
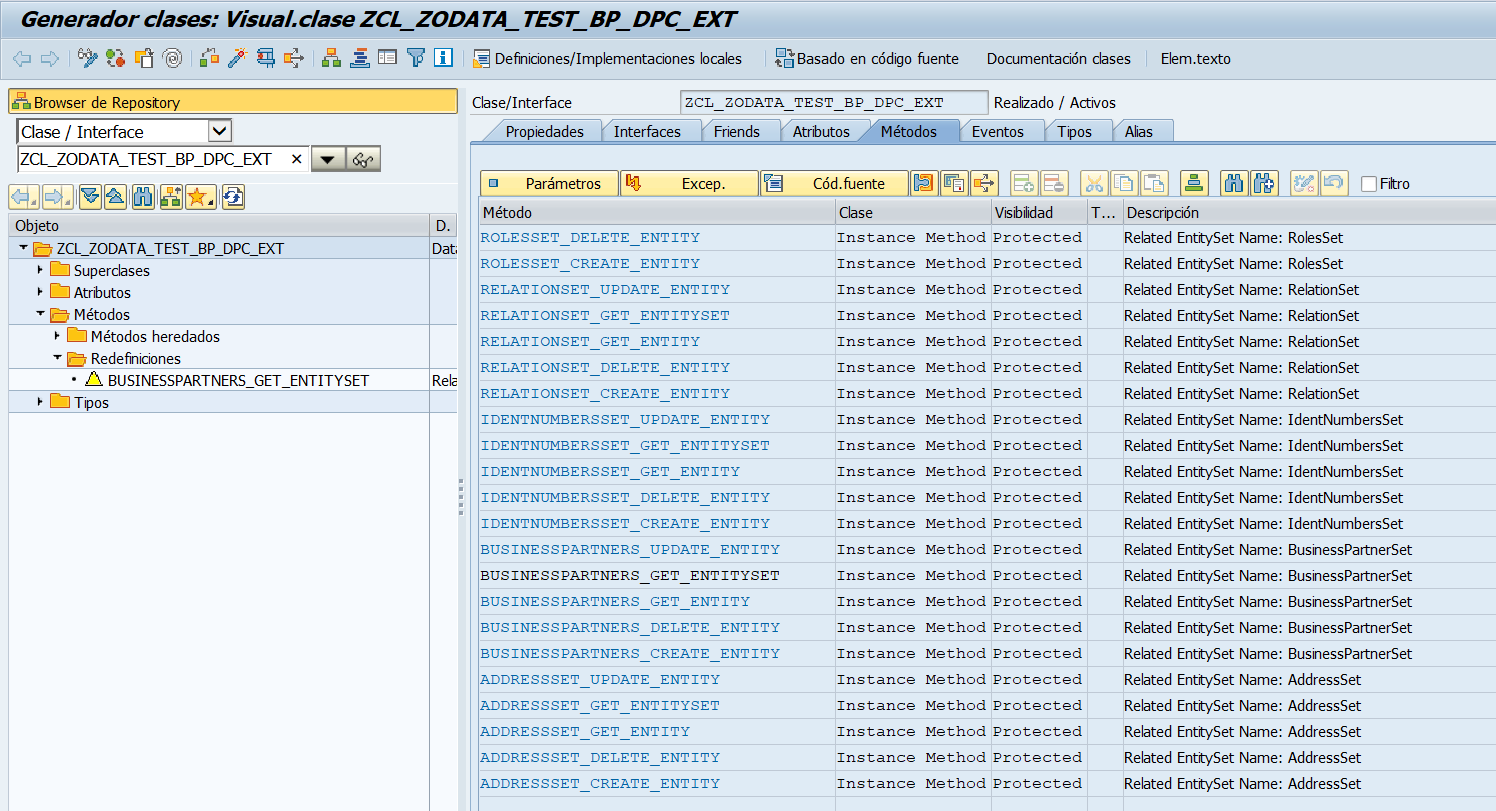
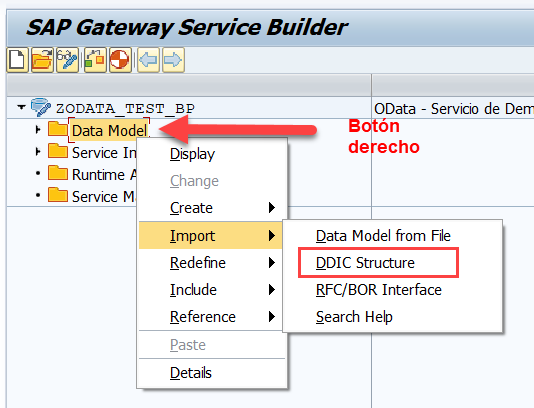
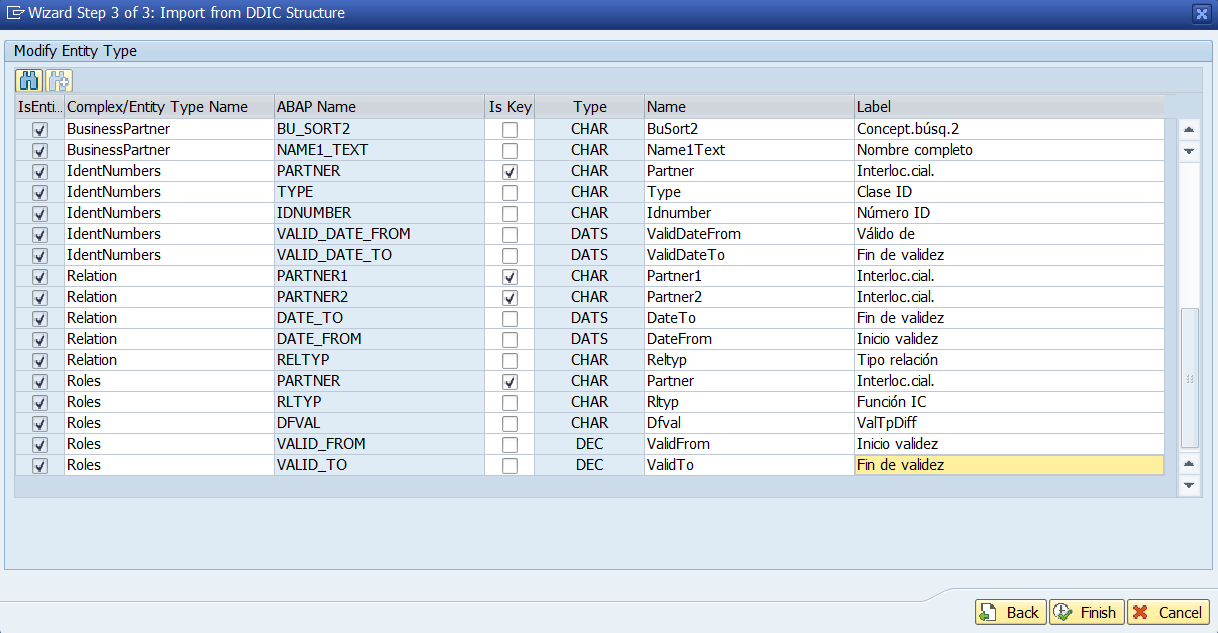
- Opciones sobre entidades y propiedades: Si repasamos el artículo OData y SAP Gateway – IV – Opciones sobre Entidades y Campos donde explicamos diversas opciones sobre entidades y propiedades de un proyecto SAP Gateway en la SEGW. Estas opciones se verán reflejadas en el OpenAPI generado, de forma que podremos ver el resultado de nuestra configuración en esta herramienta.
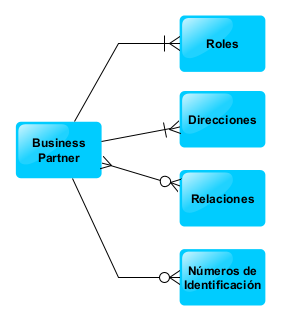
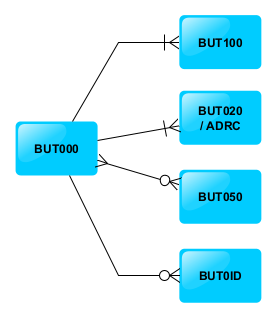
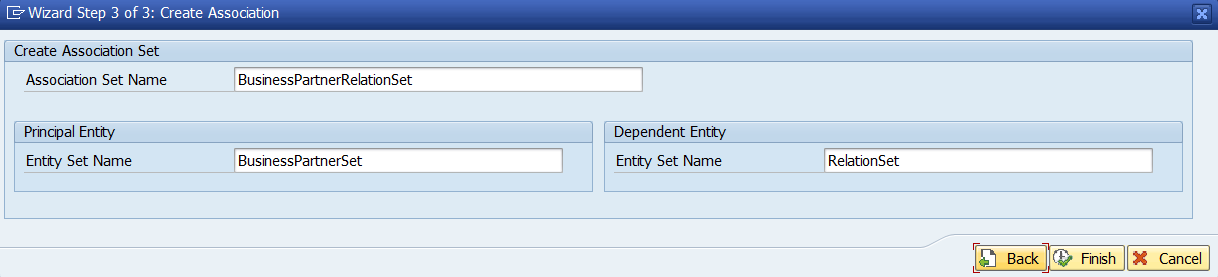
- Visualización del diagrama entidad relación: en la. Parte superior del OpenAPI generado de nuestro proyecto SAP Gateway veremos todas nuestras entidades y sus relaciones (que vimos en la entrada OData y SAP Gateway – III – Recuperar Subentidades)
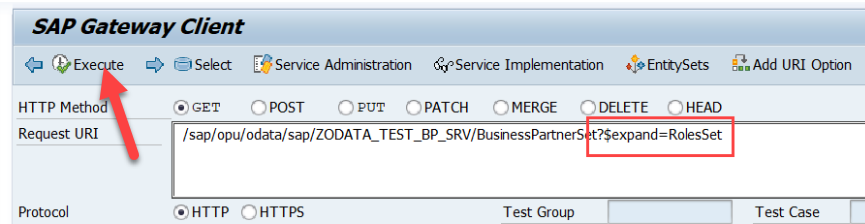
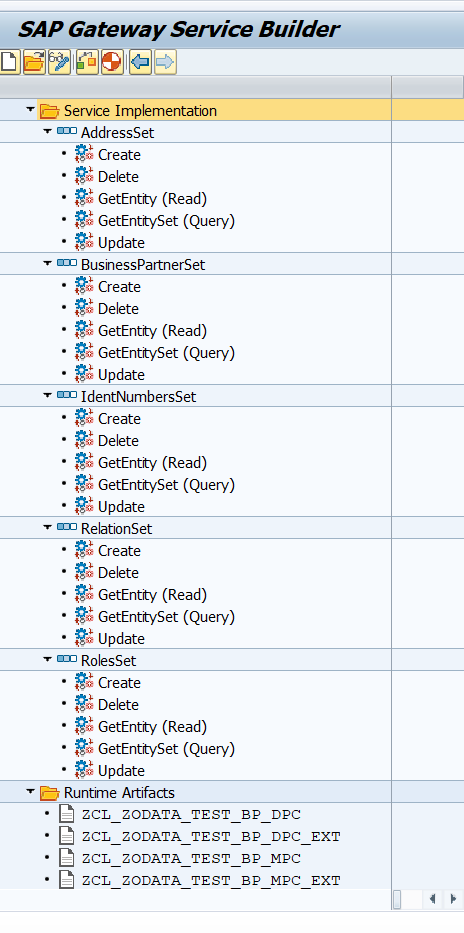
- Plantilla de ejecución de métodos sobre entidades: En base a los métodos de ejecución que se haya generado en base a las opciones de la entidad en el proyecto (GET, POST, PUT) podremos realizar pruebas en OpenAPI. La principal diferencia es que estás pruebas estarán mucho más guiadas y tendrán mucha más información que el Gateway Client. Tendremos campos para Filter, Skip, Top, Order, Select, Count, Expand, además de tener acceso directo a la documentación oficial OData de como se usa.
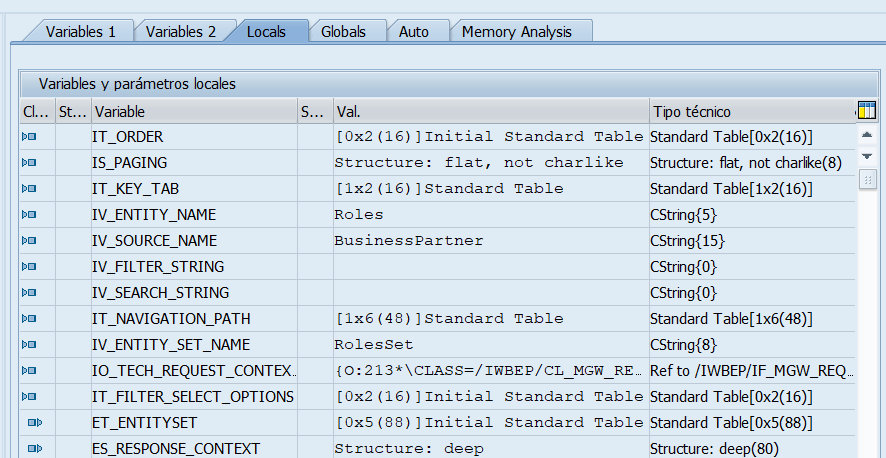
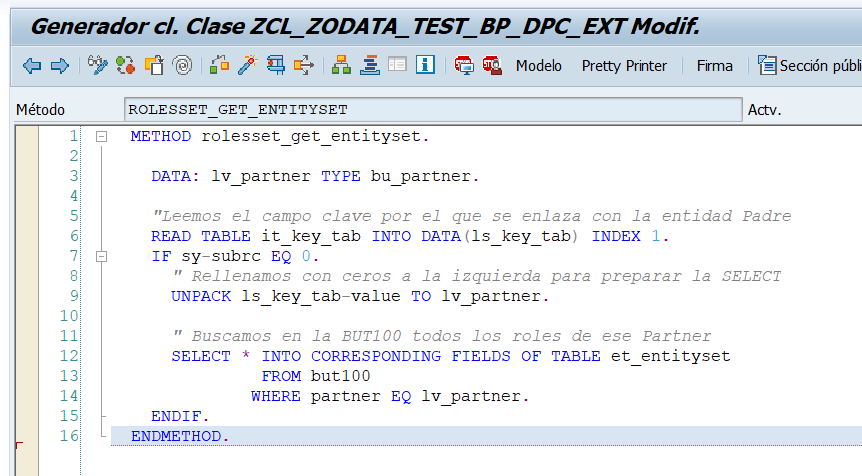
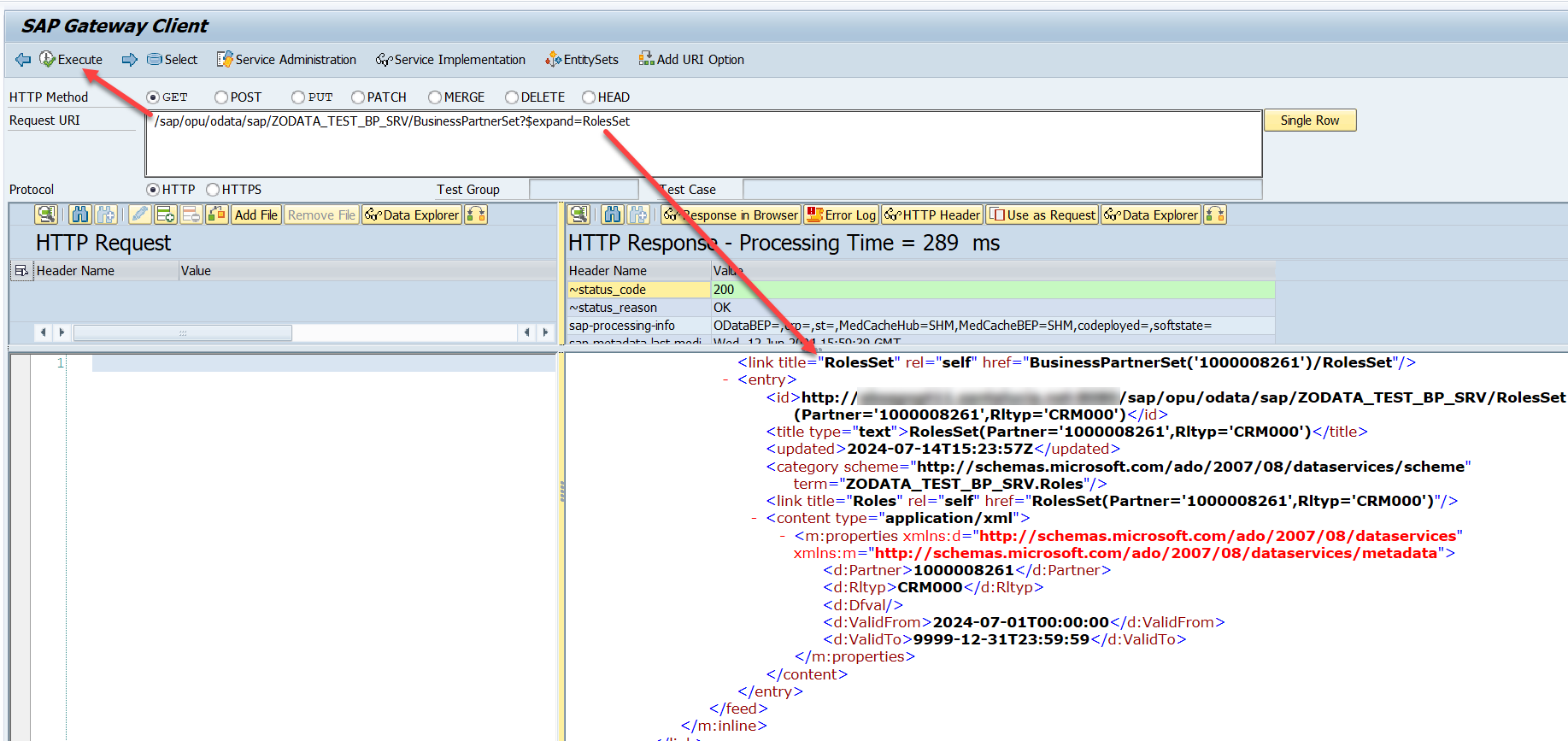
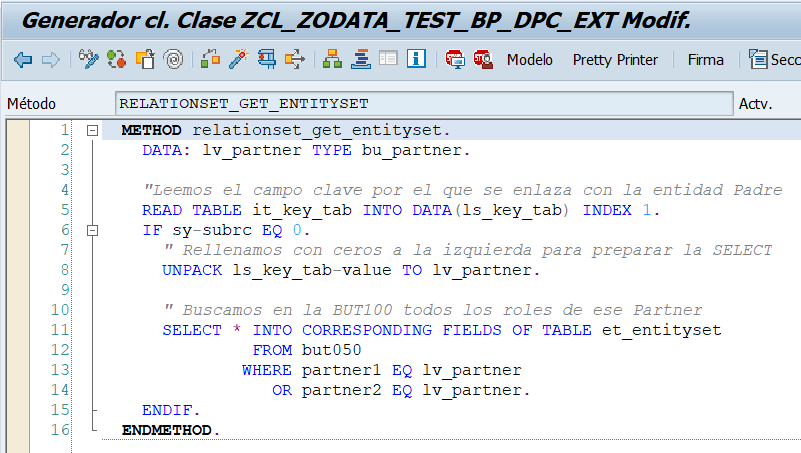
- Ejecucion OData REST de métodos sobre entidades: Una vez preparada la ejecución con todos los campos de opciones sobre la ejecución, al ejecutar podremos ver la URL de ejecución, el resultado y posibles errores. Además podremos poner un break point externo en nuestro método de la clase DPC_EXT y al ejecutar podremos capturar la ejecución en debugging.
Para mi, cuando estoy trabajando en proyectos OData en SAP es un imprescindible. Me sirve para entregar una documentación, como capa de pruebas y para ver si la configuración de mi proyecto SAP Gateway OData sea coherente.