Dentro del mundo de desarrollo de aplicaciones hay varias fases importantes, da igual la metodología que apliquemos, sea Waterfall, Agile, SAP Activate o cualquiera. Siempre hay que Analizar el requerimiento, proponer soluciones, implementarlas y finalmente probarlas para validarlas y ponerlas en producción.
Vamos a ver el trabajo que se tiene que hacer por parte de los testers, probadores o validadores de la calidad del producto entregado. Veremos que hay varias capas de equipos de pruebas para asegurar la calidad final y cual es la labor de cada uno de ellos.

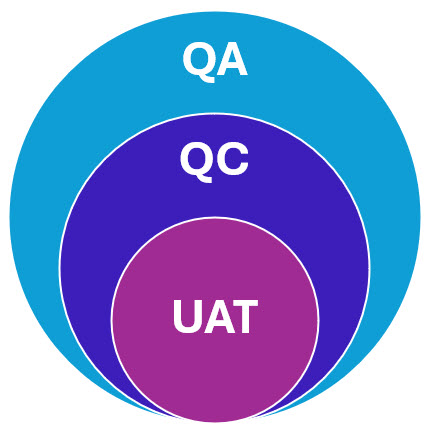
Por un lado tenemos los equipos de Calidad, QA y QC, por otro lado tenemos las pruebas de aceptación de usuario, las UATs. Y he dicho QA/QC pero eso no es un grupo de rock australiano. Se trata de dos siglas de dos equipos de trabajo en proyectos, ya sean de consultoría o de fabricación de batamantas.
- QA – Quality Assurance
- QC – Quality Control

Si bien se confunden entre sí, son dos equipos con tareas y objetivos distintos. Vamos a verlos.
¿Qué es Quality Assurance (QA)?
El Quality Assurance (QA) es básicamente un conjunto de acciones planificadas que se implementan durante el desarrollo de un producto, especialmente en software, para asegurar que todo funcione como debería antes de que llegue a las manos del cliente. ¿Cómo lo hace? Revisando y mejorando los procesos en cada fase: desde que se planea y diseña el producto, hasta su desarrollo, pruebas y despliegue. De esta manera, se minimizan los errores y se garantiza que el producto cumpla con los estándares de calidad esperados. Por lo general, en proyectos de tipo Waterfall, donde las fases son secuenciales y están muy delimitadas, se hace más énfasis es en la fase de pruebas.
De hecho en la mayoría de proyectos donde existe un equipo de QA, este se circunscribe únicamente a probar el software, eso sí, con la visión de control de errores, experiencia de usuario (UX) y pruebas de ciclo completo de integración entre sistemas. Lo cual hace que hay un equipo denominado de QA que realmente esté haciendo labores de Quality Control (QC).
¿Qué es Quality Control (QC)?
Quality Control (QC) es el proceso mediante el cual se revisa y evalúa el producto final para asegurar que cumpla con los requisitos de calidad establecidos.
El objetivo principal del QC es identificar cualquier fallo o discrepancia en el producto antes de que llegue al cliente, lo cual se logra mediante diversas pruebas, inspecciones y evaluaciones. Estas revisiones pueden incluir desde pruebas funcionales hasta revisiones visuales y de rendimiento. Si se encuentran problemas, estos se corrigen antes de lanzar el producto al mercado.
En resumen, QC se asegura de que el producto que se entrega al cliente final sea de alta calidad, revisando el resultado después de que todas las fases de desarrollo han sido completadas.
Diferencia entre Quality Assurance (QA) y Quality Control (QC)
Aunque suenan parecidos, Quality Assurance (QA) y Quality Control (QC) no son lo mismo. QA se encarga de que todo vaya bien desde el principio: se preocupa de que el proceso de desarrollo sea sólido para evitar que haya errores. QC, por otro lado, entra en acción cuando el producto ya está listo y se centra en revisar si hay problemas o defectos que se escaparon. Piensa en QA como el entrenador que te prepara para evitar errores, mientras que QC es el árbitro que señala los fallos cuando ya está todo en juego. QA trata sobre el proceso, y QC, sobre el resultado final.
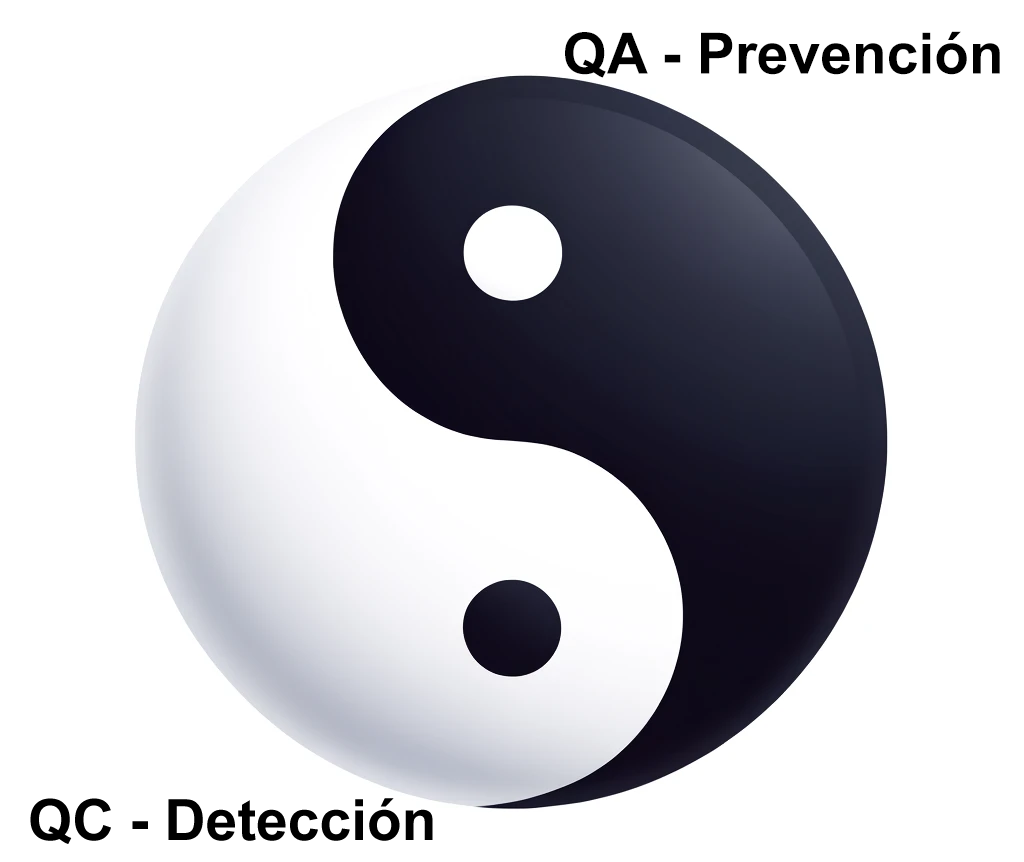
No obstante, dentro de uno hay un poco del otro y viceversa, como el yin y el yang de la gestión de calidad. Pero cada uno tiene un objetivo marcado. Aunque en ocasiones no sepamos llamar a las cosas por su nombre.
¿Qué son las UAT – User Acceptance Testing?
Las UAT (User Acceptance Testing), o pruebas de aceptación de usuario, son un tipo específico de pruebas realizadas al final del ciclo de desarrollo de software que se realizan para validar que el producto cumple con los requisitos y expectativas del usuario final o del cliente. Es el último paso antes de que el producto se implemente o se lance oficialmente.
Para mi es imprescindible que el cliente tenga perfiles especializados que hagan de enlace entre el negocio, sus peticiones de desarrollo de software y el equipo implementador. Es necesario que estos usuarios expertos sepan cómo funciona el negocio, las expectativas y cómo funciona la tecnología a aplicar. Sin estas pruebas no debe pasarse nada a producción.
En conclusión
Como hemos dicho con la metáfora del yin yang, QA y QC comparten algunas tareas, lo mismo pasa en las pruebas (de integración, UATs, etc.). Las tareas de pruebas de calidad de QC también pueden realizar se en QA y las pruebas de validación de usuario UAT son parte del control de calidad del resultado final.
A veces menos es mejor.
En un mundo ideal todo esto tendría que ser tal y cómo lo hemos explicado, tendría que haber un equipo de QA que controlase que cada parte del proyecto se realice con la calidad adecuada. Si lo piensas bien, en la mayor parte de las ocasiones esto recae en el jefe de proyecto o, incluso, en los propios consultores. Mantener documentada la toma de análisis (actas de reunión, etc), el diseño (documentos de diseño bien definidos), la implementación (plan de desarrollo, buenas prácticas, limpieza, encapsulamiento y reutilización de código) y la entrega (plan de pruebas, plan de cutover y plan de Go-Live). Pero si hubiese una figura velando porque esto se realice correctamente, estaría todo más ordenado. La parte del QC y UAT suele ser más común verlo de una forma u otra.
Por último un chiste sobre el tema que me ha parecido muy gracioso.