Has escuchado el término, incluso alguna vez has puesto cara de póker asintiendo para que no se note que no sabes lo que es un Data Lake, ni para qué sirve. Puede que lo uses y sepas qué es, pero incluso si ya lo usas, siempre viene bien entenderlo desde la base.

¿Qué es un Data Lake?
Un Data Lake es un repositorio centralizado que permite almacenar datos en su formato original, sin necesidad de estructurarlos previamente. A diferencia de un Data Warehouse, que requiere transformar los datos antes de almacenarlos (ETL), el Data Lake sigue un enfoque de ‘esquema en lectura’ (Schema-on-Read), lo que significa que los datos se estructuran únicamente al momento de ser consultados, permitiendo analizarlos en el momento que se necesiten y de la forma que requiera cada caso de uso.
Es como guardar todos los ingredientes en una despensa tal cual vienen del mercado, para cocinarlos solo cuando sabes qué receta vas a preparar, en lugar de pre-cocinarlos todos de antemano. Esto da muchísima flexibilidad para adaptarse a cualquier «receta analítica» que se requiera en el futuro.
Diferencias entre Data Lake y Data Warehouse
Mientras que un Data Warehouse almacena datos procesados y estructurados (Schema-on-Write) para responder a preguntas específicas del negocio, un Data Lake conserva los datos en su forma original, permitiendo una exploración más amplia y flexible. Esta diferencia se traduce en una mayor capacidad para descubrir patrones y obtener insights no previstos inicialmente.

Características principales de un Data Lake
Bueno, vayamos por partes, ya sabemos, nivel teórico, lo que es un Data Lake, ahora toca ver qué características principales tiene.
- Flexibilidad en el almacenamiento: Capacidad para almacenar datos de diversas fuentes y formatos, como registros de aplicaciones, datos de sensores IoT, imágenes, videos, etc.
- Escalabilidad: Diseñados para manejar petabytes de información, adaptándose al crecimiento exponencial de los datos en las organizaciones.
- Esquema en lectura: Los datos se estructuran al momento de ser consultados, lo que permite una mayor agilidad en la incorporación de nuevas fuentes de información.
- Soporte para análisis avanzados: Facilitan la aplicación de técnicas de análisis de datos, aprendizaje automático y generación de informes en tiempo real.
Beneficios y Desafíos al implementar un Data Lake
Como toda solución tiene una serie de beneficios pero también una serie de desafíos o problemas potenciales. Muchos son evidentes, vamos a verlos.
Beneficios y riesgos asociados
- Centralización de datos: Elimina los silos de información al consolidar datos de múltiples fuentes en un solo lugar.
- Riesgo asociado: Pero cuidado que el objetivo no es tirar tu basura en el Data Lake y esperar a que «se haga la magia’. Si tus datos son basura, habrás creado un cubo de basura.
- Reducción de costos: Al aprovechar tecnologías de almacenamiento de bajo costo, como las soluciones en la nube, se optimiza la inversión en infraestructura con modelos de pago como el pay-as-you-go (pago por uso)
- Riesgo asociado: si basas todo tu análisis de datos en un Data Lake alojado en «La Nube™» y no controlas ese crecimiento, tendrás dependencia excesiva con el proveedor de soluciones en la Nube y tus costos pueden ampliar. Además existe un riesgo alto de Data Egress Cost (costo que cobran los proveedores de la nube por sacar datos desde su plataforma hacia otro sistema, servicio externo o Red).
- Agilidad en el análisis: Permite a los científicos de datos y analistas acceder rápidamente a grandes volúmenes de información para realizar estudios y modelos predictivos.
- Soporte para innovación: Facilita la experimentación con nuevos enfoques analíticos y el desarrollo de soluciones basadas en inteligencia artificial.
Desafíos y consideraciones
A nivel de desafíos a enfrentar tenemos:
- Gobernanza de datos: Es esencial establecer políticas claras para la gestión, calidad y seguridad de los datos almacenados. Quién puede acceder a qué datos. La falta de control sobre accesos y calidad puede convertir el valor del dato en un riesgo operativo o legal.
- Riesgo de «Data Swamp«: Sin una adecuada organización y catalogación, un Data Lake puede convertirse en un pantano (Swamp), en un repositorio desordenado y difícil de utilizar.

- Integración con sistemas existentes: Es importante asegurar la compatibilidad y comunicación efectiva entre el Data Lake y otras plataformas de la organización.
Data Lakes en el ecosistema SAP
Obviamente, en este tema SAP no es ajeno y también ofrece soluciones que integran la funcionalidad de Data Lakes.
SAP HANA Cloud Data Lake
Permite almacenar y procesar grandes volúmenes de datos de diversas fuentes, tanto de SAP como de terceros. Esta integración facilita la realización de análisis avanzados y el desarrollo de aplicaciones inteligentes dentro del entorno SAP.
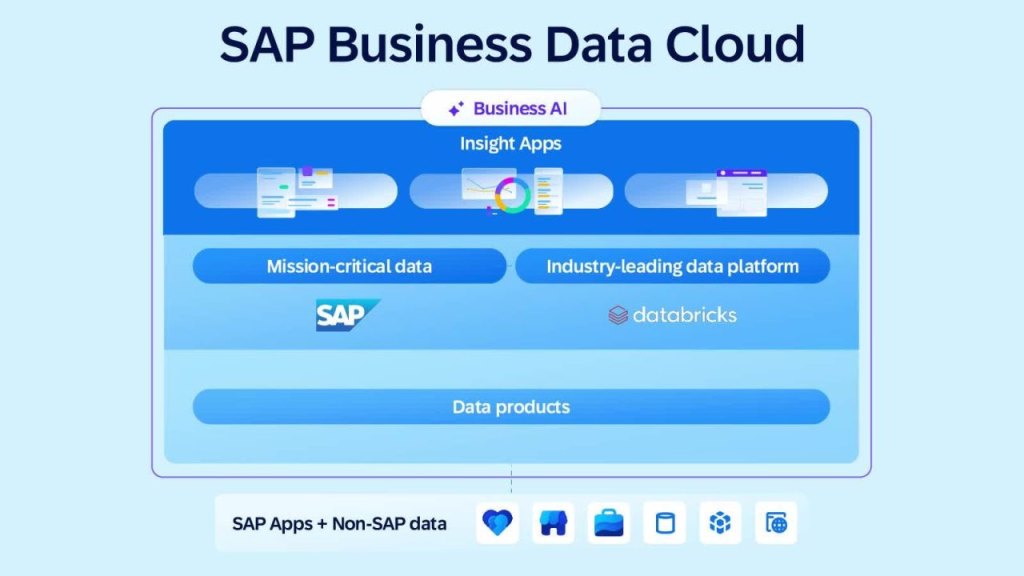
SAP Business Data Cloud
Además, en el último «SAP Unleashed» SAP anunció una revolución, SAP Business Data Cloud, donde recibir, adoptando funcionalidades propias de un Data Lake, pero con enfoque de productos de datos empresariales, datos estructurados o no estructurados de sistemas SAP o externos y desde ahí generar los «Data Products» correspondientes a conceptos de negocio. De esto ya hablaremos porque es una solución estratégica de SAP que vamos a ver en todo lo que hagamos de aquí a un tiempo.
Conclusión
Los Data Lakes representan una evolución en la gestión de datos empresariales, ofreciendo una plataforma flexible y escalable para almacenar y analizar información diversa. Pero no está exenta de desafíos y problemas, no vale tirar basura a un Data Lake.
Al adoptar correctamente esta tecnología, las organizaciones pueden mejorar su capacidad de análisis, fomentar la innovación y tomar decisiones más informadas basadas en datos. Y en el futuro presente de la Inteligencia Artificial podemos hacer beber a la IA de los datos del Data Lake para sacar conclusiones, tomar decisiones o analizar datos.

Y recuerda:

