En la entrada anterior de esta serie de artículos sobre OData ‘OData y SAP Gateway – II – Publicar un servicio OData en SAP‘ creamos un servicio muy básico de consulta de Business Partners. Ahora toca añadir más funcionalidad a ese servicio que creamos en el anterior artículo. Antes de nada, vamos a recapitular.
Serie de Artículos sobre OData
Este artículo pertenece a una serie de artículos que se van complementando poco a poco como itinerario de conocimiento:
- OData y SAP Gateway
- OData y SAP Gateway – II – Publicar un servicio OData en SAP
- OData y SAP Gateway – III – Recuperar Subentidades (Este artículo)
- OData y SAP Gateway – IV – Opciones sobre Entidades y Campos
- OData y SAP Gateway – V – Documentar y Probar con OpenAPI
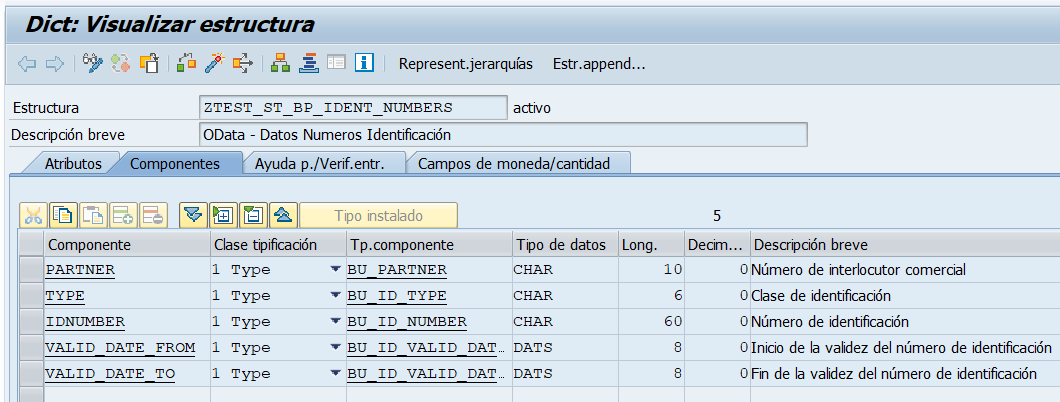
Modelo de datos
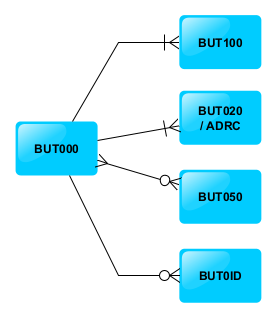
Recuperamos cómo era el modelo de datos del servicio que queríamos publicar.
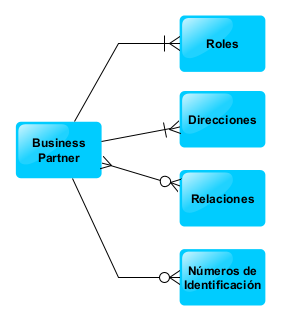
Como podemos ver en el diagrama Entidad-Relación tenemos una Entidad padre «Business Partner» que tiene cuatro entidades relacionadas:
- Roles del Business Partner
- Direcciones del Business Partner
- Relaciones del Business Partner
- Números de Identificación del Business Partner
Además, este ejemplo lo hemos hecho sencillo, con un solo nivel de relación, por tener un escenario controlado y que esto no se convierta en algo inmanejable de explicar pero, como podreis imaginar, las entidades subordinadas pueden tener otras subentidades a su vez.
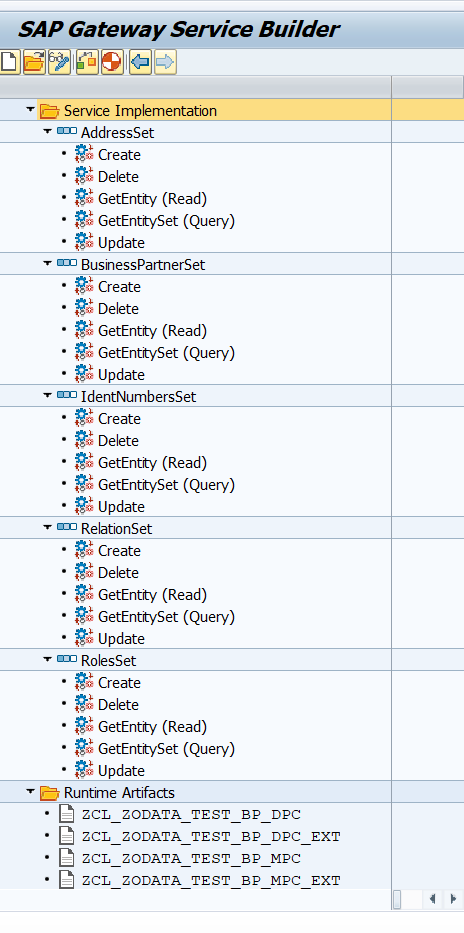
Proyecto SAP Gateway creado
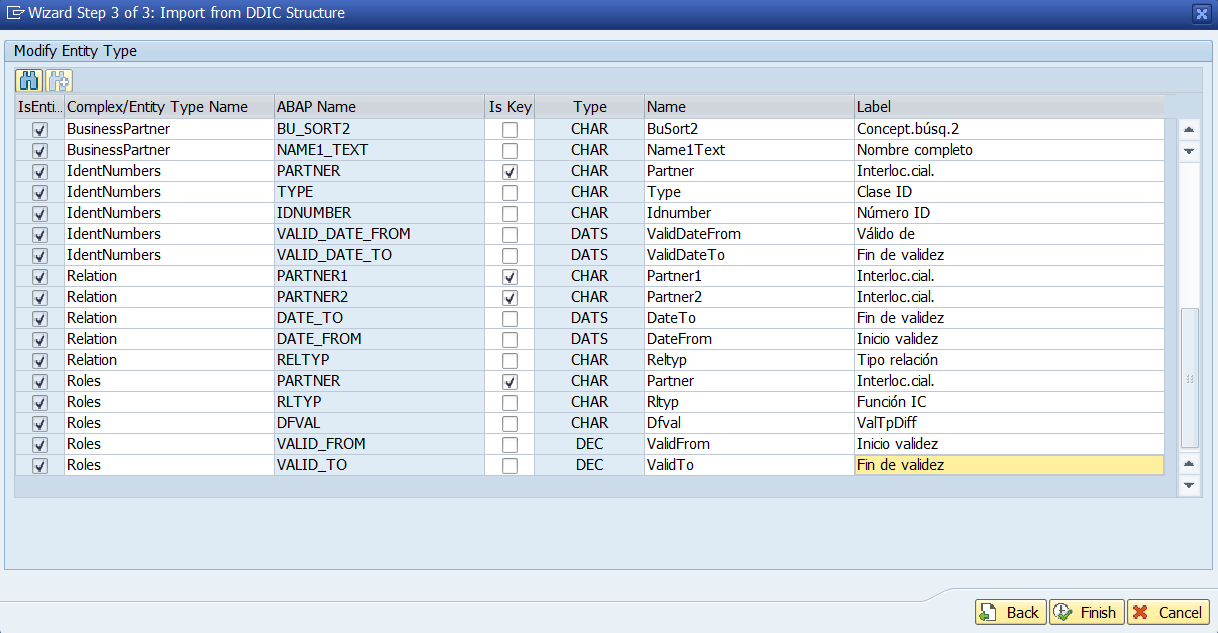
Además creamos el siguiente proyecto de Gateway con las entidades del modelo de datos y las relaciones/asociaciones.

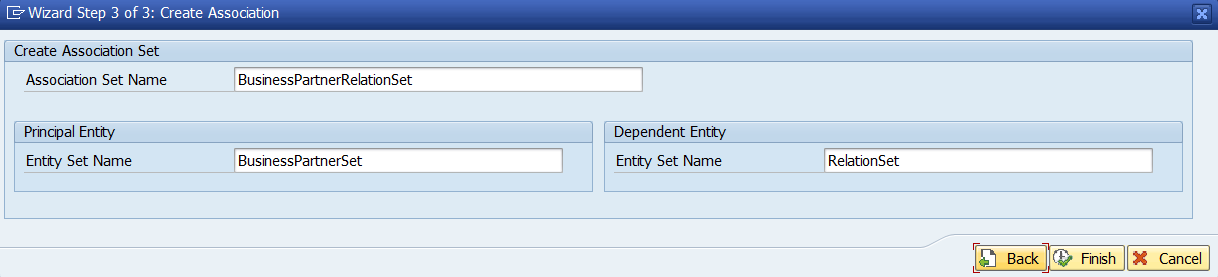
Associations Creadas
Vimos en la entrada «OData y SAP Gateway – II – Publicar un servicio OData en SAP» como creábamos Associations o relaciones entre entidades, y el resultado es el siguiente:

Donde vemos que al crear las asociaciones se crean tambien Association Sets y Navigation Properties desde la entidad Padre a las hijas.
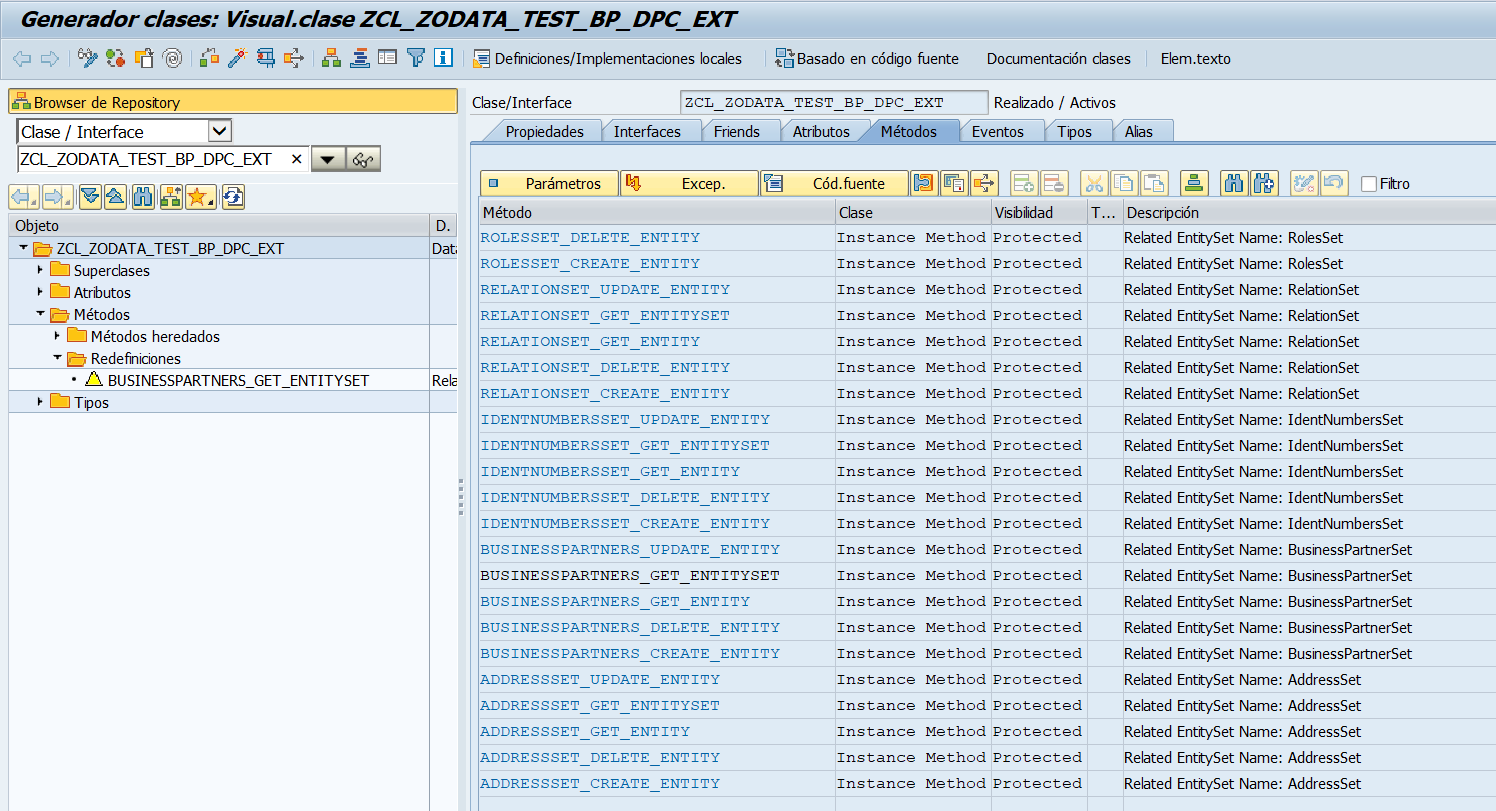
Clase de Implementación
En la clase de implementación que crea el proyecto de Gateway ZCL_ZODATA_TEST_BP_DPC_EXT redefinimos solo un método, el GET_ENTITYSET de la entidad BUSINESSPARTNERS.
Pero claro, ahora estamos hablando de relaciones entre entidades, y queremos saber cómo implementar consultas de Business Partners que nos traigan las subentidades de cada BP (Roles, Direcciones, Relaciones con otros BPs y Números de Identificación).
Para ello nos va a valer la Query simple que implementamos, pero queremos que, cuando llamemos a la consulta, nos devuelva los BPs y sus entidades relacionadas.
Uso del $expand en la consulta
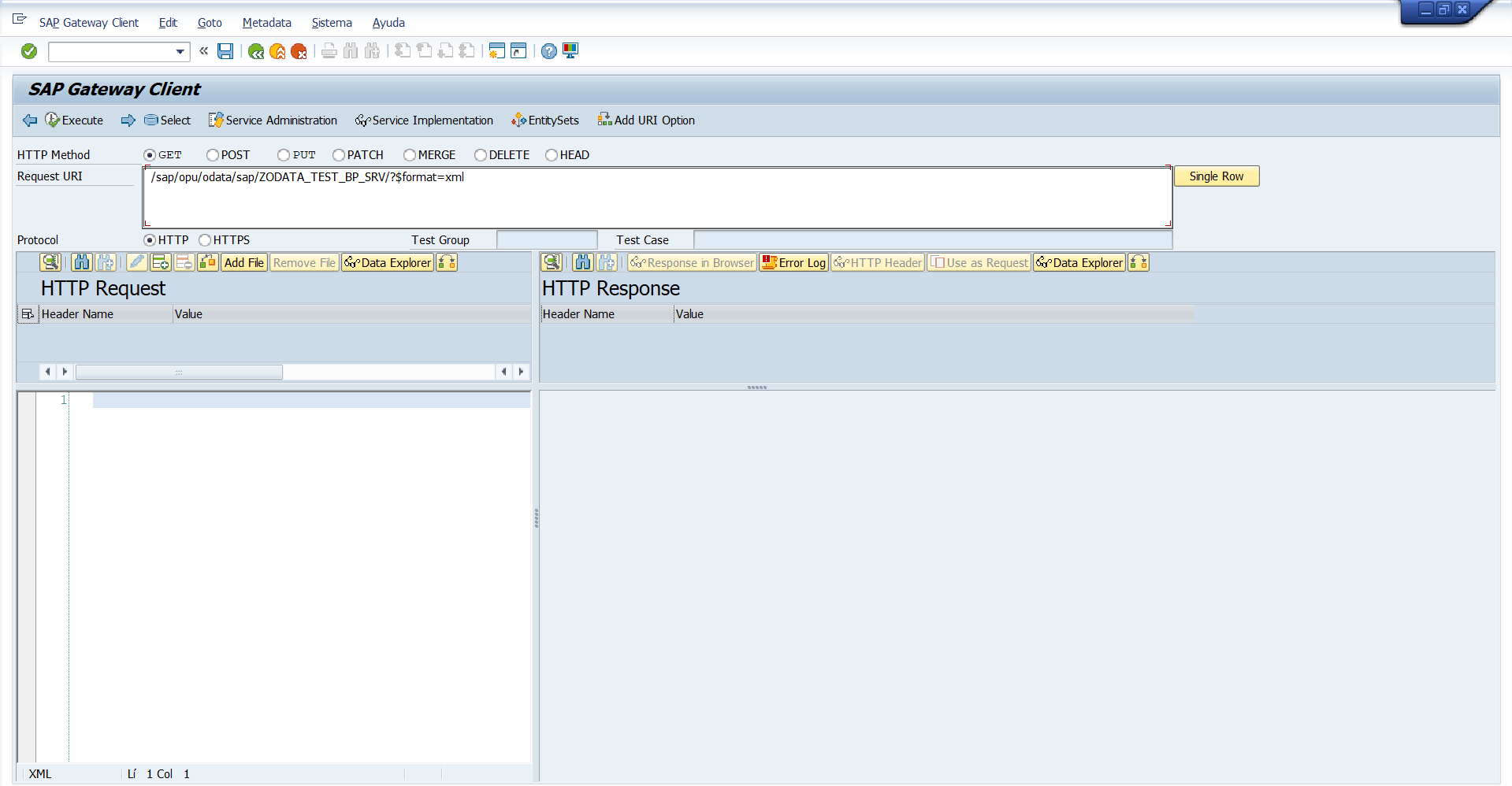
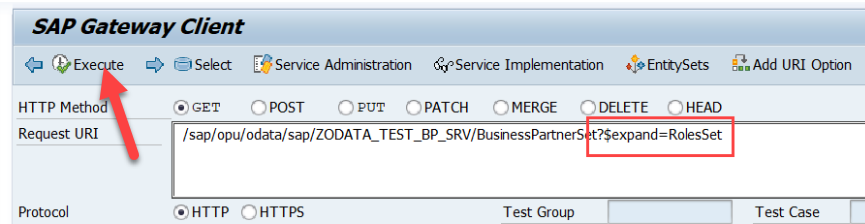
Para poder consultar las subentidades de cada entidad en una consulta, usaremos en la URL de llamada al servicio la sentencia $expand. Podemos ver la documentación oficial OData al respecto de la sentencia $expand. Por ejemplo si hacemos una búsqueda de Business Partners y, para cada uno de ellos queremos saber sus roles, realizaremos la consulta de este modo. Para ello ponemos en el Gateway Client (/IWFND/GW_CLIENT).

Pero nos da ese error, y esto es porque no hemos implementado el método del GET_ENTITYSET (dame la colección de datos) de la entidad ROLES.
Implementar el GET_ENTITYSET
Para implementar el GET_ENTITYSET nos iremos a nuestra clase Z*DPC_EXT y buscaremos el GET_ENTITYSET de nuestra entidad que queremos consultar. Y redefinimos el método.

Pero claro, una vez redefinido, tenemos que implementar la lógica al respecto de esa acción (GET_ENTITYSET) de esa entidad (ROLES). Vemos que en la firma del método tenemos muchos parámetros de entrada y un par de salida. Son los siguientes:

Parámetros de Entrada
- IV_ENTITY_NAME: Nombre de la entidad que se va a manejar en el método. Normalmente, cuando hablamos de métodos propios de una entidad concreta, como es el caso, será irrelevante. Pero en otras ocasiones se trata de métodos genéricos, donde tenemos que cambiar la lógica de la acción propuesta en base a este método.
- IV_ENTITY_SET_NAME: Lo mismo que el anterior pero con el EntitySet.
- IV_SOURCE_NAME: Nos dirá si partimos de una entidad superior o no y cual es.
- IT_FILTER_SELECT_OPTIONS: Tabla con los campos de selección que se hayan usado para la búsqueda del EntitySet mediante la sentencia $filter. En este caso si hemos añadido algún criterio de selección para los Roles. Puedes ver la documentación oficial OData sobre el FILTER.
- IS_PAGING: Nos indica el TOP y SKIP para la consulta, esto sirve para acotar el número de resultados y poder paginar. Por ejemplo, si tenemos 1000 registros pero ponemos un TOP de 100 y un SKIP de 500, recuperaremos del 501 al 600. Puedes ver la documentación oficial OData sobre el TOP y SKIP.
- IT_KEY_TAB: Si hemos accedido a la entidad por una clave, la suya o la de una entidad superior, en el campo KEY TAB vendrán las claves por las que se accede al EntitySet.
- IT_NAVIGATION_PATH: Tabla que contiene la ruta de navegación entre entidades.
- IT_ORDER: Tabla con los criterios de ordenación deseados para recuperar los datos de la colección del EntitySet. Puedes ver la documentación oficial OData sobre ORDERBY.
- IV_FILTER_STRING: El string de búsqueda con los campos y los valores buscados. Es una forma distinta de manejar los criterios de búsqueda de la tabla IT_FILTER_SELECT_OPTIONS.
- IV_SEARCH_STRING: Permite realizar búsquedas de texto completo en los datos de una entidad. Este parámetro permite indicar una cadena de búsqueda que se aplicará a varios campos de la entidad, haciendo más fácil encontrar registros que contengan el texto indicado en cualquier parte de esos campos.
- IO_TECH_REQUEST_CONTEXT: Este parámetro proporciona información técnica sobre la solicitud actual. Contiene detalles relevantes del contexto técnico de la llamada al servicio OData, permitiendo acceder a datos importantes para el procesamiento de la solicitud. Desde este parámetro podemos recuperar mucha información:
- Usuario llamante
- Cabecera HTTP
- Parámetros de la URL
- IP del cliente
- Parámetros de la Query
Parámetros de Salida
- ET_ENTITYSET: Tabla de datos de salida de la consulta para devolver el conjunto de entidades (EntitySet) solicitado. Es una tabla interna, con el tipo de datos de la entidada, que contiene los datos que se devuelven al cliente como resultado de la consulta. Por lo tanto, es la tabla resultado que tenemos que rellenar con los datos buscados una vez aplicados los criterios de entrada.
- ES_RESPONSE_CONTEXT: Es una estructura de salida de la consulta OData, contiene metadatos sobre la respuesta, como el número de registros devueltos, información de paginación, y cualquier mensaje de error o advertencia.
Implementación de ROLESET_GET_ENTITYSET
Bueno, mucha explicación de lo que son todos los parámetros que se manejan en el GET_ENTITYSET pero no mostramos cómo hacerlo en la práctica. Como es imposible abarcarlo todo en un artículo, los ejemplos de implementación serán sencillos, para complicarlo está la definición de los parámetros del GET_ENTITYSET.
Lo primero que vamos a hacer es ver qué nos llega en la entrada cuando usamos un $expand desde la entidad padre. Para ello, lo que queremos es parar la ejecución en ese método, lo que yo hago es poner una sentencia absurda para poder poner un Breakpoint externo.

Al ejecutar de nuevo la llamada en el Gateway Client (/IWFND/GW_CLIENT)
Se abre la sesión debug en el breakpoint externo y podemos ver los datos que nos vienen:
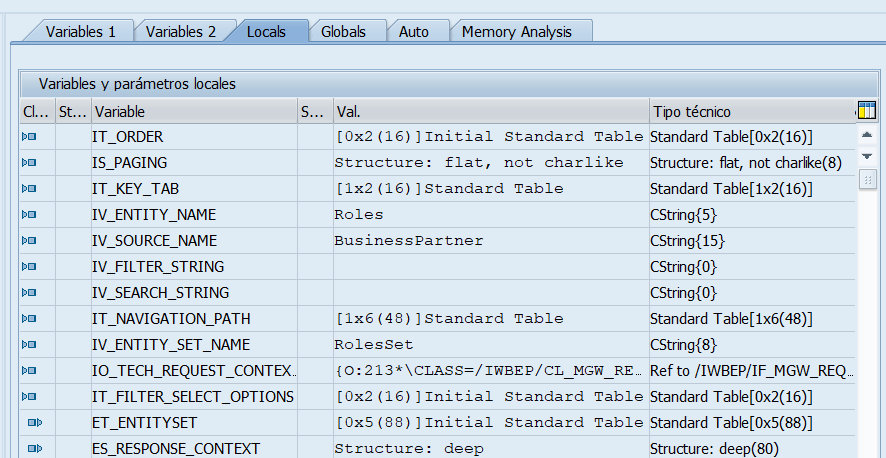
Ahora podemos ver la definición de cada campo que hemos hecho arriba para entenderlo. Vemos que la entidad buscada (IV_ENTITY_NAME) es «Roles» que el origen (IV_SOURCE_NAME) es «BusinessPartner», que no tiene criterios de búsqueda añadidos, ni paginación, ni orden,que la tabla IT_NAVIGATION_PATH tiene un registro con la navigation properties RolesSet desde BusinessPartner, y tiene una clave en la tabla IT_KEY_TAB.

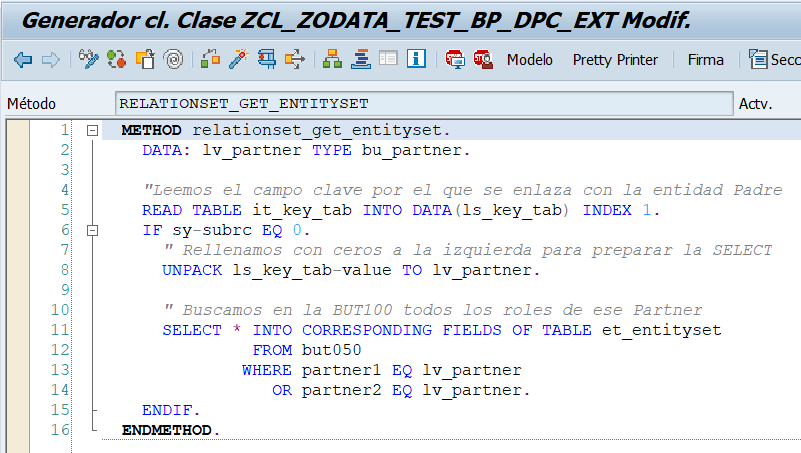
Ahora, teniendo el campo Partner en la tabla IT_KEY_TAB vamos a implementar la lógica para rellenar el RolesSet.
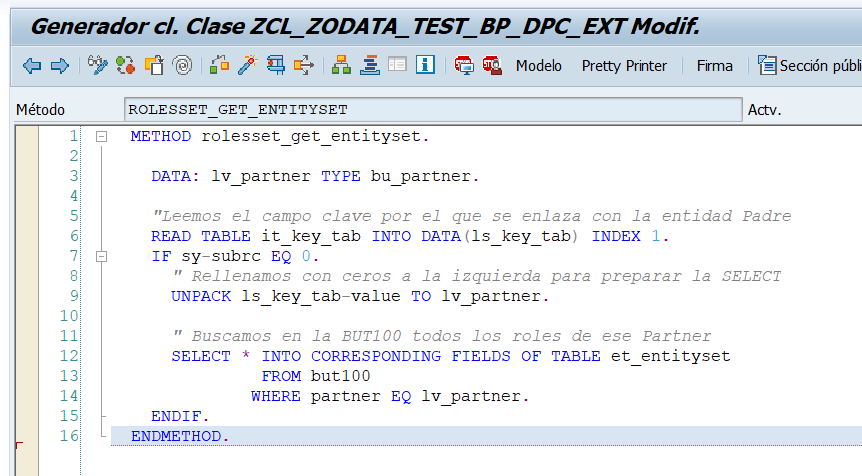
Si ahora ejecutamos nuestra sentencia ya veremos datos de los roles de cada uno de los registros de Business Partners.
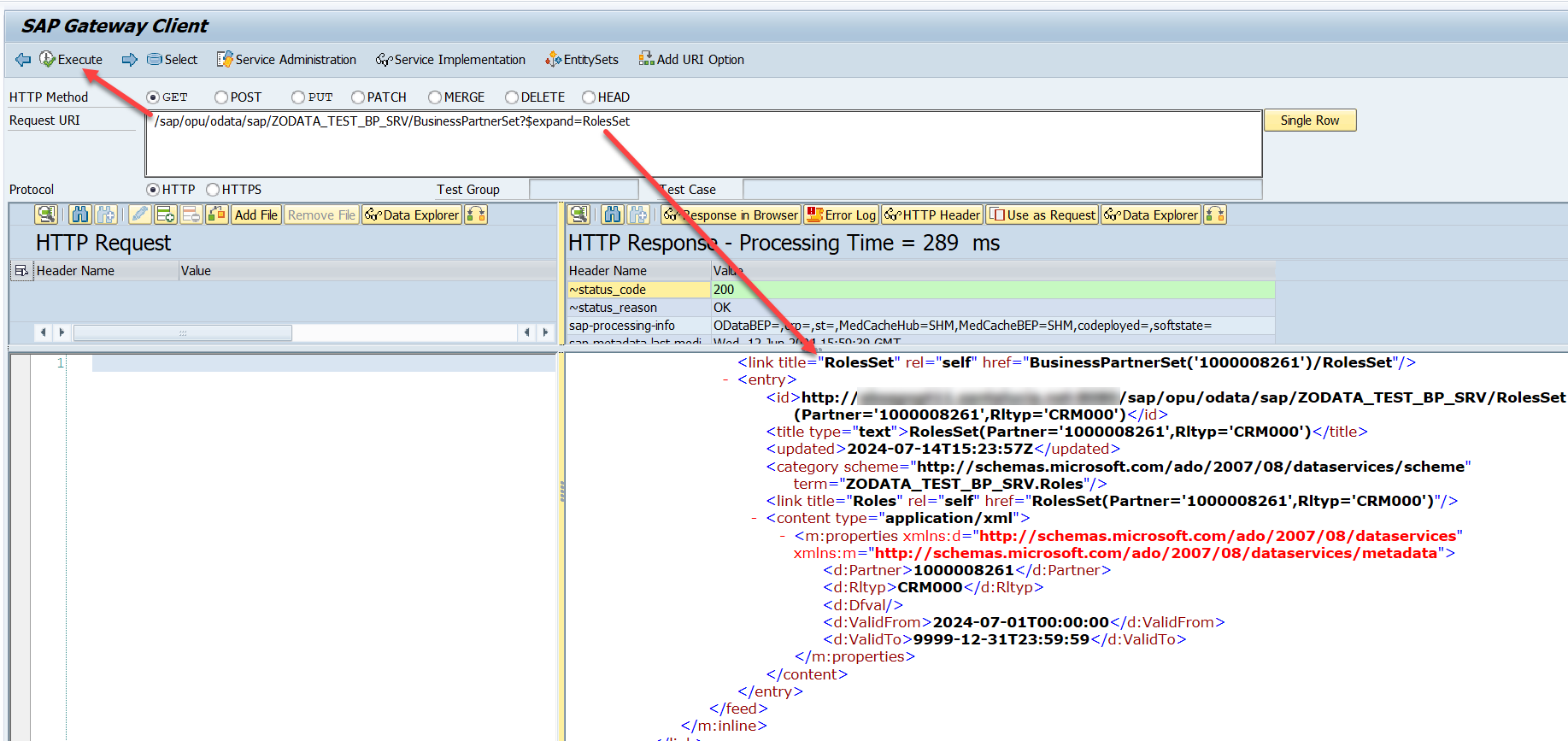
Implementar GET_ENTITYSET del resto de entidades
Una vez tengamos implementado el GET_ENTITYSET de las subentidades nuestra clase Z*DPC_EXT quedará de este modo:

Y para el que le interese los GET_ENTITYSET quedarán de esta forma:


Seleccionar las entidades a recuperar
Pero claro, tenemos cuatro subentidades subordinadas de BusinessPartner. ¿Cómo tenemos que hacerlo? Para hacerlo pondremos en la sentencia $expand las subentidades que queramos recuperar, separadas por coma. En nuestro ejemplo la sentencia total sería:
/sap/opu/odata/sap/ZODATA_TEST_BP_SRV/BusinessPartnerSet?$expand=RolesSet,IdentNumbersSet,AddressSet,RelationSetEl resultado será que, para cada Business Partner, tendremos su colección de Roles, Números de Identificación, Direcciones y Relaciones. Por supuesto, para cada subentidad, tendremos que implementar su GET_ENTITYSET correspondiente.
Lo importante de esto es que podemos elegir qué subentidades recuperar, haciendo la recuperación de datos selectiva y dependiente del llamante.