En otros lenguajes de programación que no están tan ligados al núcleo de un aplicativo empresarial, es común y casi obligatorio ver el uso de control de versiones y repositorios como GitHub, GitLab, etc. para gestionar y colaborar en el desarrollo del código. Sin embargo, en el caso de ABAP, un lenguaje que está profundamente arraigado dentro del framework SAP Netweaver, que tiene su propio repositorio y gestor de versiones, la adopción de herramientas modernas como Git para ABAP ha sido más lenta.
Es aquí donde abapGit entra en escena, proporcionando una solución clave para los desarrolladores ABAP que quieren aprovechar las ventajas del control de versiones distribuido. Pero antes de nada, veamos el escenario habitual en otros lenguajes y en entorno de desarrollo conjunto distribuido. Lo primero que tenemos que saber es qué es eso de Git.
¿Qué es Git?
Git es un sistema de control de versiones distribuido diseñado para rastrear los cambios en archivos de código fuente y facilitar la colaboración entre múltiples desarrolladores en un proyecto. Fue creado por Linus Torvalds en 2005, inicialmente para el desarrollo del Kernel de Linux. Es utilizado principalmente en el desarrollo de software, pero también puede aplicarse a otros tipos de proyectos donde se necesita llevar un control detallado de cambios en archivos.
Características Claves de Git
Las características que hacen de Git una tecnología tan potente son:
Control de versiones distribuido: A diferencia de los sistemas centralizados de control de versiones, en Git cada desarrollador tiene una copia completa del historial del proyecto en su máquina local, lo que permite trabajar de manera independiente y sin conexión.
Snapshots: En lugar de registrar diferencias entre versiones de los archivos, Git toma «instantáneas» del estado de los archivos en cada commit. Si no hay cambios en un archivo, Git solo referencia la versión anterior.
Integración y colaboración: Git facilita la integración continua y la colaboración mediante ramas (branches), que permiten que varios desarrolladores trabajen en diferentes características de un proyecto sin interferir con el trabajo de otros. Posteriormente, las ramas pueden fusionarse (merge) de manera segura.
Rendimiento eficiente: Dado que Git opera de manera distribuida y guarda versiones localmente, la mayoría de las operaciones (como commits, comparaciones y creación de ramas) son extremadamente rápidas, ya que no dependen de un servidor remoto.
Compatibilidad con plataformas como GitHub: Git es la tecnología subyacente que soporta plataformas populares como GitHub, GitLab, Bitbucket, las cuales añaden características adicionales como la gestión de proyectos, seguimiento de errores y funciones de revisión de código.
Beneficios de usar Git
Seré breve, os podéis imaginar los beneficios, viendo las características clave.
Seguridad: El historial de cambios en Git está protegido contra alteraciones accidentales o malintencionadas.
Flexibilidad: Git es útil para proyectos de cualquier tamaño y es compatible con numerosos flujos de trabajo.
Desarrollo paralelo: Facilita el trabajo simultáneo de varios desarrolladores en diferentes partes de un proyecto, permitiendo integraciones y fusiones de código (Merge) sin perder la coherencia del proyecto.
Ya sabemos lo que es Git y sus características, pero nos falta saber que es eso de Github o GitLab.
¿Qué es GitHub?
GitHub es una plataforma de desarrollo colaborativo que permite a los programadores y equipos gestionar proyectos de software utilizando el sistema de control de versiones Git. GitHub proporciona un entorno basado en la web donde los desarrolladores pueden alojar y compartir sus proyectos de código, colaborar en equipo, y realizar un seguimiento de los cambios mediante el uso de repositorios.
No vamos a profundizar más en GitHub, puesto que esta basado en Git (ya lo hemos explicado) aportando una capa por encima con más funcionalidades de gestión de Proyectos.
Vamos ahora, una vez sabemos lo que es Git y lo que es GitHub (o similares), vamos a ver qué es abapGit.
¿Qué es abapGit?
Como podemos ver en la Help de SAP:
abapGit es un cliente Git desarrollado por código abierto para que el servidor ABAP importe y exporte objetos ABAP entre sistemas ABAP.
Con abapGit, puede exportar sus objetos ABAP de cualquier sistema a otro, normalmente de local a en la nube o de un sistema en la nube a otro.
Pero en SAP BTP es un framework donde desplegar aplicaciones de muchos tipos ya sea SAP Build Apps, Fiori, CPI, Python, Go, Ruby, etc. Digamos que en el framework de trabajo de SAP BTP usar una solución Git es practicamente obligatorio.
Pero nosotros vamos a algo más mundano, queremos integrar la tecnología Git dentro de nuestros proyectos ABAP de toda la vida, con su SE80, SE38, sus paquetes de desarrollo, etc.
Por lo tanto, podemos decir que abapGit es un cliente de Git específico para ABAP, que permite a los desarrolladores trabajar con un control de versiones distribuido externo dentro del entorno SAP. Desarrollado como un proyecto de código abierto por la comunidad, abapGit permite exportar e importar objetos ABAP a repositorios externos como GitHub, GitLab o Bitbucket, lo que hace posible integrar flujos de trabajo modernos en sistemas SAP.
¿Qué puedo hacer con abapGit?
Pues SAP tiene varios tutoriales que nos pueden ayudar con esto:
Podemos ampliar esas dos tareas que propone el Learning de SAP por la siguiente lista:
Versionado del código ABAP: Permite realizar Commits del código ABAP en un repositorio Git (GitHub, GitLab, etc), creando un historial de cambios que facilita la colaboración entre múltiples desarrolladores.
Colaboración en equipo: Con la capacidad de clonar y fusionar repositorios, los equipos de desarrollo pueden trabajar en diferentes características del proyecto simultáneamente sin interferir entre sí, lo que mejora la productividad y reduce los errores.
Migración de código ABAP entre sistemas: abapGit facilita la migración de objetos ABAP de un sistema on-premise a la nube, o entre diferentes sistemas SAP. Esto es especialmente útil en proyectos de migración a SAP S/4HANA o SAP BTP. Esto es lo que comenta el enlace de SAP Learning que he puesto antes.
Integración con herramientas CI/CD: abapGit permite integrar proyectos ABAP en flujos de trabajo de integración y entrega continua (CI/CD), facilitando un enfoque ágil al desarrollo.
Exportación e importación de objetos: abapGit facilita la exportación de objetos ABAP, como clases, funciones, y programas, a repositorios Git. Desde allí, es posible importar estos objetos a otros sistemas SAP, lo que simplifica la colaboración entre diferentes entornos de desarrollo. Y esto es lo que comenta el otro enlace de SAP Learning que he puesto. Sobre este punto, quiero hacer una puntualización en el punto siguiente.
Importación de funcionalidad colaborativa: Existen proyectos de código abierto subidos a GitHub con funcionalidades concretas que están a nuestra disposición para importarlos en nuestro sistema SAP por medio de abapGit. Obviamente, con esto hay que tener cierto cuidado porque estamos importando código de otra persona. Tienen que ser fuentes contrastadas y validadas por la comunidad. Pero, para mi, es un aspecto fundamental ya que alimenta el conocimiento global y simplifica muchas tareas que alguien ya pensó e implementó. Ejemplos de esto pueden ser:
OpenAPI: El motivo de escribir esta entrada es básicamente poder explicar OpenAPI en SAP para nuestros servicios OData. Por lo tanto este punto lo explicaremos en la entrada correspondiente, cuando la publique actualizaré esta para poder el link.
ABAP2XLS: Proporciona un conjunto de opciones para el trabajo con excel desde ABAP, simplifica mucho el proceso de manejar Excel con muchas demos y muchas opciones.
¿Cómo instalar abapGit en mi sistema?
Pues es bastante sencillo, más que nada porque está perfectamente explicado en varios sitios. Por ejemplo:
Standalone version: Se trata de un report que sirve para realizar la conexión de Importación (que puede ser desde un repositorio tipo GitHub) y Exportación a local.
Developer version: Es la versión que te permite trabajar con tus proyectos ABAP en un repositorio Git con toda la funcionalidad. Importar, Exportar, trabajar colaborativamente, etc. Para esta versión tienes que instalar primero la versión Standalone para descargarte el proyecto abapGit tal y como comenta el tutorial. Ten en cuenta que quizás tengas que instalar el certificado de GitHub en el sistema para poder establecer la conexión con GitHub, viene bien explicado en SSL Setup. También se puede instalar de forma offline descargándote el proyecto en Zip y subiéndolo al report de Standalone.
Y es que Git no solo vale para la gestión de cambios y trabajo concurrente, como hemos visto aporta la funcionalidad de Integración con herramientas CI/CD, esto ¿Qué es?.
Integración Continua (CI)
La Integración Continua es una práctica en la que los desarrolladores integran su código en un repositorio compartido, como puede ser GitHub, varias veces al día. Cada vez que se hace una integración, se ejecuta una serie de pruebas automáticas para asegurarse de que el nuevo código no introduzca errores ni rompa las funcionalidades existentes. El objetivo es detectar y corregir problemas lo más rápido posible.
Entrega Continua (CD)
Ojo cuidado con esto. en la Entrega Continua, una vez que el código pasa las pruebas automáticas y es integrado, se prepara automáticamente para su despliegue en el entorno de producción.
Obviamente, en estas prácticas se puede llegar a la profundidad que se requiera, no es todo o nada. Hay mucho más que aprender de CI/CD pero yo no soy el más indicado para explicar más allá de la teoría. Para mi, viniendo del mundo SAP, con su cola de transportes, su paso a producción bajo ticket de Remedy o Service Now, y sus UATs, me parece complicado y peligroso. No obstante SAP ya está en ello, podemos ver la charla de SAP Teched 2020 «DevOps for ABAP? Try the Git-Enabled Change and Transport System | SAP TechEd in 2020«
Madre mía!
Podéis verlo en este video.
En Conclusión
El objetivo de esta entrada es servir de base a otras entradas en las que hago uso de ABAPGit para importar proyectos ABAP en el sistema. Es muy útil, ya no solo para tener un repositorio de tus desarrollo, si no también para utilizar proyectos ABAP de la comunidad que aporten valor inmediato a tu proyecto.
Llevo desde los 18 años programando, y empecé por curiosidad y en casa. Es algo que se me da bien, me gusta y me genera satisfacción «crear» algo donde no lo había. Mi perfil profesional actual es bastante amplio, pero nunca quiero dejar ese aspecto de mi día día. Es algo que me llena, que me alegra…. hasta que veo algunas masacres de código que hay por el mundo, que me entran ganas de matar.
if dino_aux2-tipo = ‘velociraptor’ and dino_aux2-enfadado = ‘true’ or dino_tocho = ‘suelto’. Write:/ ‘Me voy’. endif. Viendo tu código te tenían que haber despedido hace tiempo, pero no habría película
Hoy voy a hablar de la calidad del código, no solo en su efectividad, también en su eficiencia, su facilidad de lectura y mantenimiento. A muchos les parecerá una tontería, algo sin importancia, pero un buen código simplifica mucho el mantenimiento, la reutilización, la lectura y documentación.
CleanABAP
Existe un proyecto en GitHub llamado Clean ABAP donde la comunidad de desarrolladores ABAP han sacado una guía de estilo de desarrollo ABAP con las mejores prácticas. Además está en varios idiomas, incluido el Español lo puedes ver aquí.
Y claro, yo iba a escribir mi libro de buenas prácticas desde mi punto de vista. Cosa que he hecho en algún proyecto al ver los desastres que la gente generaba en el sistema. Pero, al ver que ya había un consenso entre desarrolladores ABAP, y que no estaba solo en esto, pues mejor. Lo que voy a hacer es extraer de la guía de estilo CleanABAP aquellas recomendaciones que vea más necesarias. En la guía de estilo (lectura recomendadísima), se dividen las recomendaciones por áreas, vamos a respetarlas por si quieres ir a ver la fuente.
NOTA: Si estás viendo esto desde un móvil o tablet mejor en horizontal, las líneas de código se te van a cortar y hay cosas que no entenderás. No obstante, es preferible que lo leas desde el PC.
Formato
Optimiza para lectura, no para escritura
Siempre escribe pensando en la legibilidad del código, no en lo rápido que puedas escribirlo.
Bueno, yo con esta ya si que me corto las venas. Es un &#+%€ botón, pulsar un botón y te hace gran parte del trabajo.
Usa el Pretty Printer.
Usa el Pretty Printer
En serio. Usa el Pretty Printer.
Usa la configuración de Pretty Printer de tu equipo
Enlazado con lo anterior, tampoco estamos hablando de ingeniería. Es configurar tu Pretty Printer para que actúe de la forma que se consensue en tu equipo de trabajo. Yo, personalmente me gusta así:
Y esto es por lo siguiente:
Sangrar: Obvio, que el texto tenga sus correspondientes sangrías que te indiquen el nivel en el que estás es fundamental.
Conversión mayúsc./minúsc.: A mi me parece muy interesante que las palabras clave sean mayúsculas para ver claramente la acción que se está realizando e identificar las sentencias ABAP de variables, parámetros y literales.
" Ejemplo sin palabras clave mayúsculas select partner into lv_partner from but000 where bu_group = lv_clientes and xdele = abap_false and type = 1.
" Ejemplo con palabras clave mayúsculas SELECT partner INTO lv_partner FROM but000 WHERE bu_group = lv_clientes AND xdele = abap_false AND type = 1.
Por favor, usa el Pretty Printer.
No más de una sentencia por línea de código
Cada línea de código debe contener solo una sentencia, evitando mezclar varias operaciones en una sola línea.
Para mi esto es especial para los IFs con múltiples condiciones. Todo de seguido no se ve claramente.
" Ejemplo Incorrecto IF lv_total > 100 And lv_is_customer = 'X' AND lv_country = 'ES'. lv_discount = lv_total * 0.1. ELSE. lv_discount = 0. ENDIF.
" Ejemplo Correcto IF lv_total > 100 AND lv_is_customer = 'X' AND lv_country = 'ES'. lv_discount = lv_total * 0.1. ELSE. lv_discount = 0. ENDIF.
Aquí la posición de los AND y OR ya es manía personal, hay quien los pone al principio, a mi me gusta ponerlo al final y alinear las variables, los operadores y los AND/OR.
Mantén una longitud de línea razonable
Si la línea de código es demasiado larga, divídela en varias líneas para que sea más fácil de leer y seguir.
" Ejemplo Incorrecto SELECT carrid connid fldate FROM sflight INTO TABLE lt_sflight WHERE carrid = 'LH' AND connid = '0400' AND fldate = '20231010'.
" Ejemplo Correcto SELECT carrid connid fldate INTO TABLE lt_sflight FROM sflight WHERE carrid = 'LH' AND connid = '0400' AND fldate = '20231010'.
Vamos, no hay color. Mi manía personal es ponerlo en ese orden (SELECT, INTO, FROM, WHERE), y alineando desde el INTO. Además con las sentencias ABAP alineadas el código tiene más aire y se lee mejor. Se identifica claramente qué se selecciona, a donde se guarda, de qué tablas y con qué condiciones.
Usa una línea en blanco para separar cosas, pero no más
Utiliza una línea en blanco para separar lógicamente secciones del código, como declaraciones de variables y bloques de código, pero evita poner líneas en blanco innecesarias.
Los bloques de sentencias han de estar separados para su entendimiento. Todo junto no se lee bien.
" Ejemplo Incorrecto DATA: ls_order TYPE zorder, lv_total TYPE p DECIMALS 2, lv_discount TYPE p DECIMALS 2. ls_order-order_id = 'ORD001'. ls_order-customer_id = 'CUST001'. ls_order-status = 'OPEN'. lv_total = 500. lv_discount = lv_total * 0.1. ls_order-total_amount = lv_total. ls_order-discount_amount = lv_discount. INSERT zorder FROM ls_order.
" Ejemplo Correcto DATA: ls_order TYPE zorder, lv_total TYPE p DECIMALS 2, lv_discount TYPE p DECIMALS 2.
Alinea asignaciones al mismo objeto, pero no a objetos diferentes
Cuando asignas valores a varios atributos de un mismo objeto, puedes alinearlos para mejorar la legibilidad, pero evita alinear asignaciones entre diferentes objetos.
" Cómo lo hago yo lo_instance->set_data( EXPORTING iv_name = lv_name iv_age = lv_age iv_address = lv_address iv_order_id = lv_order_id ).
Fíjate en el alineamiento de los =, hace que sepas claramente identificar parámetros de variables. Esto también lo suelo hacer los IFs con los comparadores, pero eso ya es manía personal.
" Ejemplo Incorrecto IF lv_status EQ 'A' AND lv_subtype NE 'X' AND lv_amount GT 100. lv_result = 'Valid'. ELSE. lv_result = 'Invalid'. ENDIF.
" Cómo lo hago yo IF lv_status EQ 'A' AND lv_subtype NE 'X' AND lv_amount GT 100. lv_result = 'Valid'. ELSE. lv_result = 'Invalid'. ENDIF.
Nomenclatura
Usa nombres descriptivos
Los nombres de variables, clases y métodos deben ser lo suficientemente claros para que cualquier desarrollador entienda su propósito sin necesidad de contexto adicional. Por ejemplo
" Declaraciones no descriptivas DATA: lv_amt TYPE i, lt_cust TYPE TABLE OF but000, lt_items_aux TYPE TABLE OF crmd_orderadm_i.
" Declaraciones con nombres descriptivos DATA: lv_total_amount TYPE i, lt_customers TYPE TABLE OF but000, lt_items_completed TYPE TABLE OF items.
No cuesta nada y se lee todo mejor, eso sí, se consecuente con usar cada uno para lo que es, no vayas a meter en lt_items_completed cualquier tipo de posiciones de pedido porque te venga bien.
Usa sustantivos para las clases y verbos para los métodos
Las Clases deberían representar conceptos o entidades y, por lo tanto, se nombran como sustantivos.
" Ejemplos order_calculator order_utils
Los Métodos representan acciones o comportamientos, por lo que deben nombrarse con verbos.
Para mejorar la legibilidad en ABAP, se prefiere el uso de snake_case en lugar de camelCase o PascalCase en variables y métodos. El uso de snake_case es una convención ampliamente utilizada en el código ABAP debido a su compatibilidad con otras herramientas del ecosistema SAP y porque ayuda a mejorar la claridad del código, haciéndolo más legible y fácil de seguir para los desarrolladores.
" Ejemplos Incorrectos DATA: TotalAmountDue type p decimals 2. DATA: itemstoadd type table of items.
" Ejemplos Correctos DATA: lv_total_amount_due TYPE p DECIMALS 2, lt_items_to_add TYPE TABLE OF items.
Constantes
Usa constantes en lugar de números mágicos
Evita usar números sin contexto directamente en el código. En su lugar, define constantes para mejorar la legibilidad.
" Ejemplo Incorrecto IF lv_value > 42.
" Ejemplo Correcto IF lv_value > gc_max_allowed.
Sabemos que el 42 es «El sentido de la vida, el universo y todo lo demás» pero a lo mejor en tu proceso no es el sentido de ese número. Usa constantes, puedes declararlas en un INCLUDE TOP o bien en una clase estática que aglutine varias constantes.
Prefiere clases de enumeración a interfaces de constantes
Esto lo he añadido por el punto anterior. Lo que yo suelo hacer es crear una serie de clases UTIL con métodos estáticos, con un sentido funcional cada una, y sus constantes correspondientes. Voy a poner un ejemplo:
CLASS zcl_crm_ofertas_util DEFINITION. PUBLIC SECTION.
" Constantes para los estados de la oferta CONSTANTS: c_estado_abierto TYPE char10 VALUE 'E0001', c_estado_cerrado TYPE char10 VALUE 'E0002'.
" Métodos estáticos CLASS-METHODS: get_datos_oferta IMPORTING iv_oferta_id TYPE char10 RETURNING VALUE(rt_oferta_datos) TYPE TABLE OF zcrm_oferta.
CLASS-METHODS: get_interlocutores IMPORTING iv_oferta_id TYPE char10 RETURNING VALUE(rt_interlocutores) TYPE ztt_interlocutores. ENDCLASS.
Y las constantes c_estado_abierto y c_estado_cerrado podemos usarlo en cualquier código para comprobar si un pedido tiene ese estado.
IF lv_estado_pedido EQ zcl_order_util=>c_estado_abierto. " Hacer cosas ENDIF.
Variables
Prefiere declaraciones in-line que al inicio
Este apartado no estoy al 100% de acuerdo, porque soy de vieja escuela, antes de que las declaraciones In-line estuviesen disponibles y suelo hacer bastantes declaraciones al inicio. No obstante, creo que tiene bastante razón.
" Ejemplo Incorrecto METHOD calculate_discount. DATA: lv_discount TYPE p DECIMALS 2, lv_total_amount TYPE p DECIMALS 2, lt_clientes TYPE TABLE OF but000.
SELECT * INTO TABLE @DATA(lt_clientes) FROM but000 WHERE bu_group EQ zcl_bp_util=>c_agrupación_cliente. ENDMETHOD.
Lo importante es conocer las declaraciones In-line que son muy útiles y aportan claridad y limpieza al código.
No encadenes declaraciones
Cada declaración debe ocupar una línea por sí misma. Esto facilita el seguimiento de las variables.
" Ejemplo Incorrecto DATA: lv_value TYPE i, lv_discount TYPE p, lv_total TYPE p.
" Ejemplo Correcto DATA: lv_value TYPE i, lv_discount TYPE p, lv_total TYPE p.
A lo que yo añado lo siguiente
Usa «DATA:» y evita usar múltiples DATA
Entras en un código y te encuentras con esto
DATA lv_es_cliente TYPE bu_partner. DATA lt_pedidos_abiertos TYPE TABLE OF zpedidos. DATA ls_pedidos_abiertos TYPE zpedidos. DATA lv_fecha_creacion TYPE datum. DATA lv_sociedad TYPE werks. DATA lt_pedidos_cerrados TYPE zpedidos.
Pero ¿Para qué ponemos tantos DATA. Si ponemos solo un DATA: el Pretty Printer se va a encargar de darle mucho aire y alinear los TYPE.
DATA: lv_es_cliente TYPE bu_partner. lt_pedidos_abiertos TYPE TABLE OF zpedidos. ls_pedidos_abiertos TYPE zpedidos. lv_fecha_creacion TYPE datum. lv_sociedad TYPE werks. lt_pedidos_cerrados TYPE zpedidos.
Vamos. no hay color, y eso que he puesto un ejemplo con seis líneas, he llegado a ver decenas de DATA juntos. Ya sabes, usa el Pretty Printer.
Tablas
Prefiere INSERT INTO TABLE a APPEND TO
Usar INSERT INTO TABLE es más versátil y claro para la inserción de datos en tablas internas. Además el uso del APPEND da errores en las tablas de tipo SORTED y en INSERT INTO TABLE lo gestiona bien.
" Ejemplo Incorrecto APPEND ls_cliente TO lt_clientes.
" Ejemplo Correcto INSERT ls_cliente INTO TABLE lt_clientes.
Ocupa lo mismo y no da problemas.
Prefiere LINE_EXISTS a READ TABLE o LOOP AT
En lugar de leer tablas para verificar si una línea existe, usa la función LINE_EXISTS, que es más clara y eficiente. Esto no lo suelo usar mucho, porque soy vieja escuela, pero me parece muy interesante.
" Ejemplo Incorrecto READ TABLE lt_table WITH KEY id = lv_id TRANSPORTING NO FIELDS. IF sy-subrc = 0. WRITE: 'La línea existe'. ELSE. WRITE: 'La línea no existe'. ENDIF.
" Ejemplo Correcto IF line_exists( lt_table[ id = lv_id ] ). WRITE: 'La línea existe'. ELSE. WRITE: 'La línea no existe'. ENDIF.
Strings
Usa | para construir textos
En ABAP, puedes usar | para concatenar y construir cadenas de forma más limpia que con las antiguas funciones CONCATENATE.
" Ejemplo menos eficiente CONCATENATE lv_name lv_surname INTO lv_fullname.
Este es uno de los principios básicos de CleanABAP. Es mejor hacer un método que haga una cosa cada vez para que el código se pueda leer de forma sencilla y coherente. Para que el método haga una cosa nos tenemos que asegurar que:
Tiene pocos parámetros: Un método que hace una sola cosa debería tener pocos parámetros de entrada. Tener muchos parámetros indica que el método podría estar haciendo más de una tarea
No tiene parámetros booleanos de entrada: Los parámetros booleanos en un método pueden ser una señal de que el método realiza dos cosas: una cuando el valor es verdadero y otra cuando es falso.
Tiene exactamente un parámetro de salida: Un método que hace una sola cosa debería tener solo un resultado. Si devuelve más de un valor, probablemente esté realizando múltiples tareas
Es corto: Un método debe ser corto y directo. Si un método es demasiado largo, es una señal de que está realizando múltiples tareas.
Desciende un nivel de abstracción: Un buen método debe enfocarse en un solo nivel de abstracción. No debe mezclar operaciones de bajo nivel (como acceso a base de datos) con operaciones de alto nivel (como lógica de negocio)
Lanza un solo tipo de excepción: Si un método lanza múltiples tipos de excepciones, es probable que esté haciendo más de una cosa
No puedes extraer más métodos de él con un significado claro: Si no puedes dividir un método en varios métodos más pequeños que tengan un propósito claro y diferenciado, entonces probablemente el método está bien estructurado.
No puedes agrupar sus sentencias en secciones lógicas: Si las sentencias de un método se pueden agrupar en diferentes secciones, es probable que el método esté realizando múltiples tareas.
Mensajes
Haz que los mensajes sean fáciles de encontrar
Para hacer los mensajes fáciles de encontrar en una búsqueda desde la transacción SE91. Realmente yo usaba la sentencia incorrecta, pero la recomendación es no usar eso.
" Ejemplo Incorrecto IF 1 = 2. MESSAGE e001(ad). ENDIF.
" Ejemplo Correcto MESSAGE e001(ad) INTO DATA(message).
Comentarios
Exprésate en código, no en comentarios
El código bien escrito debe ser lo suficientemente claro para no requerir comentarios excesivos.
" Ejemplo Incorrecto " Calcula el total con el descuento lv_total = lv_total - lv_discount.
Usa nombres descriptivos en lugar de comentarios, ya que esto hace el código más autoexplicativo.
Los comentarios no son excusa para nombrar mal objetos
Los nombres de variables y objetos deben ser claros y descriptivos por sí mismos, sin depender de comentarios para su explicación.
" Ejemplo Incorrecto " Cantidad Total DATA: lv_tot_amnt TYPE i.
" Ejemplo Correcto DATA: lv_total_amount TYPE i.
El nombre de la variable debe ser suficientemente descriptivo para evitar depender de comentarios innecesarios.
Usa métodos en lugar de comentarios para segmentar tu código
Es más eficiente y claro usar métodos con nombres descriptivos para organizar las diferentes tareas dentro del código. Esto mejora la legibilidad y el mantenimiento del código, además de seguir el principio de hacer una sola cosa en cada método.
Los comentarios pueden volverse obsoletos o estar mal escritos, lo que puede generar confusión. Sin embargo, los métodos con nombres claros y bien definidos hacen que el propósito de cada sección sea evidente, eliminando la necesidad de comentarios explicativos.
" Ejemplo Incorrecto METHOD process_order. " Validación del cliente IF lv_customer_id IS INITIAL. RETURN. ENDIF.
" Calcular el total lv_total = calculate_total( lt_items ).
" Aplicar el descuento IF lv_discount > 0. lv_total = lv_total - lv_discount. ENDIF.
" Guardar el pedido en la base de datos save_order( lv_order_id ). ENDMETHOD.
METHOD save_order. INSERT INTO zorders VALUES iv_order_id. ENDMETHOD.
El diseño va en los documentos de diseño, no en el código
Evita incluir detalles de diseño en el código, ya que esto pertenece a la documentación externa. El diseño debe documentarse fuera del código para evitar que el código se vuelva innecesariamente complicado de leer.
" Ejemplo Incorrecto " Este método sirve para crear pedidos de venta con los datos de " entrada de cliente, datos organizativos, productos y precios. " Los tipos de posición se calcularán en base al tipo de cliente y el " tipo de pedido que se quiere crear. " Para eso se llamará a la tabla ZTB_TIPO_POS y se recuperarán los " tipos de posición. " El estado del pedido será siempre "Abierto" METHOD crear_pedido_ventas.
Nadie se lee esto, además puede quedar fácilmente obsoleto al cambiar el contenido del método. Si el código se entiende, no hace falta hacer explicaciones de más.
Usa » para comentar, no *
Es preferible usar » para líneas de comentario porque se identan automáticamente al nivel donde aplican al usar Pretty Printer.
" Ejemplo Incorrecto CASE lv_estado. WHEN c_abierto. * Comentario en abierto
WHEN c_en_proceso. * Comentario en proceso
WHEN c_cerrado. * Comentario en cerrado
ENDCASE.
" Ejemplo Correcto CASE lv_estado. WHEN c_abierto. " Comentario en abierto
WHEN c_en_proceso. " Comentario en proceso
WHEN c_cerrado. " Comentario en cerrado
ENDCASE.
Borra el código en lugar de comentarlo
El código obsoleto debe ser eliminado en lugar de ser comentado para evitar confusión. Para algo está la gestión de versiones, el código que pasa por muchas manos y correcciones se vuelve imposible de leer.
No agregues prototipos ni comentarios de fin de métodos (INTERESANTE)
Los comentarios estándar de la firma de métodos o performs no aportan valor y generan ruido en el código. Estos comentarios pueden haber tenido sentido décadas atrás, cuando los entornos de desarrollo eran limitados, pero en los entornos modernos de ABAP (SE24, SE80, ABAP Development Tools en Eclipse), ya no son necesarios, porque la firma del método está fácilmente accesible con herramientas integradas.
" Ejemplo Incorrecto *&---------------------------------------------------------------------* *& Form CHECK_ORDER *&---------------------------------------------------------------------* * text *----------------------------------------------------------------------* * -->P_LV_ABAP_BOOL text * -->P_LV_COUNTRY text * -->P_LV_CUSTOMER_ACTIVE text * -->P_LV_HAS_DISCOUNT text * <--P_LV_TOTAL text * <--P_LV_SPECIAL_CUSTOMER text *---------------------------------------------------------------------- FORM check_order USING p_lv_abap_bool p_lv_country p_lv_customer_active p_lv_has_discount CHANGING p_lv_total p_lv_special_customer.
" Ejemplo Correcto FORM check_order USING p_lv_abap_bool p_lv_country p_lv_customer_active p_lv_has_discount CHANGING p_lv_total p_lv_special_customer.
En Conclusión
Me ha quedado algo largo, y eso que he hecho una selección de las recomendaciones que me parecen más interesantes. A pesar de eso, además yo tengo alguna manía más que realizo en mi día a día (no voy a añadir más leña). En entradas posteriores seguiremos hablando de esto pero desde un punto de vista de comprobar la calidad del código existente.
Por último, si solo me tuviese que quedar un un básico, diría:
En la entrada anterior de esta serie de artículos sobre OData ‘OData y SAP Gateway – II – Publicar un servicio OData en SAP‘ creamos un servicio muy básico de consulta de Business Partners. Ahora toca añadir más funcionalidad a ese servicio que creamos en el anterior artículo. Antes de nada, vamos a recapitular.
Serie de Artículos sobre OData
Este artículo pertenece a una serie de artículos que se van complementando poco a poco como itinerario de conocimiento:
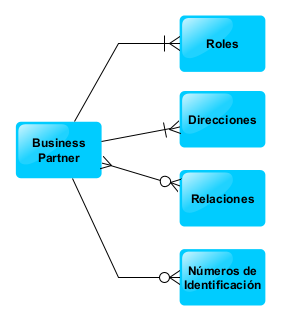
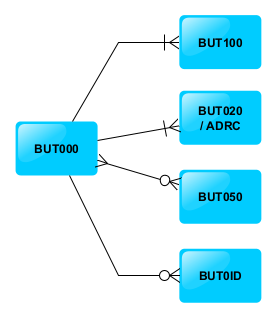
Recuperamos cómo era el modelo de datos del servicio que queríamos publicar.
Como podemos ver en el diagrama Entidad-Relación tenemos una Entidad padre «Business Partner» que tiene cuatro entidades relacionadas:
Roles del Business Partner
Direcciones del Business Partner
Relaciones del Business Partner
Números de Identificación del Business Partner
Además, este ejemplo lo hemos hecho sencillo, con un solo nivel de relación, por tener un escenario controlado y que esto no se convierta en algo inmanejable de explicar pero, como podreis imaginar, las entidades subordinadas pueden tener otras subentidades a su vez.
Proyecto SAP Gateway creado
Además creamos el siguiente proyecto de Gateway con las entidades del modelo de datos y las relaciones/asociaciones.
Donde vemos que al crear las asociaciones se crean tambien Association Sets y Navigation Properties desde la entidad Padre a las hijas.
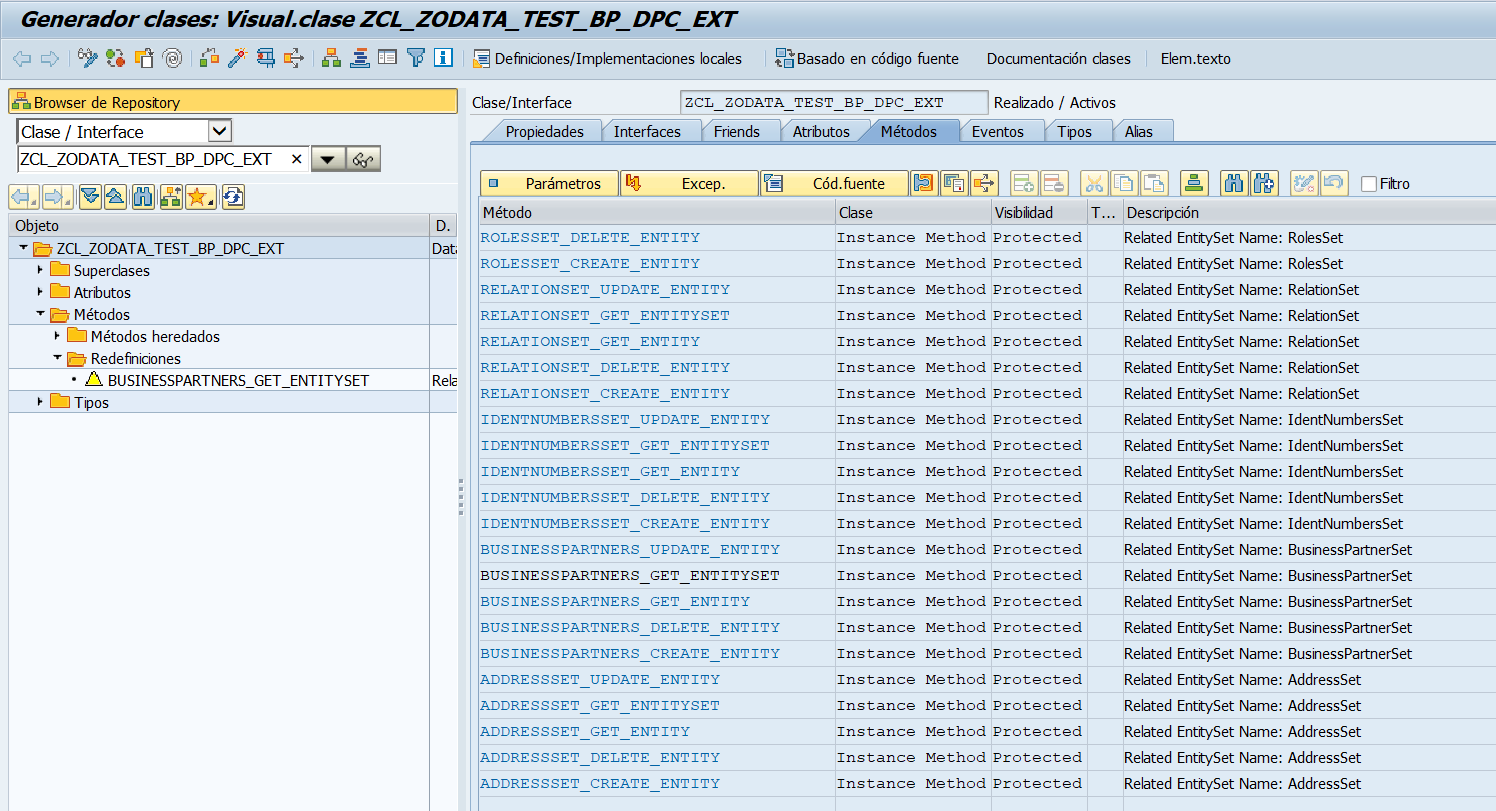
Clase de Implementación
En la clase de implementación que crea el proyecto de Gateway ZCL_ZODATA_TEST_BP_DPC_EXT redefinimos solo un método, el GET_ENTITYSET de la entidad BUSINESSPARTNERS.
Pero claro, ahora estamos hablando de relaciones entre entidades, y queremos saber cómo implementar consultas de Business Partners que nos traigan las subentidades de cada BP (Roles, Direcciones, Relaciones con otros BPs y Números de Identificación).
Para ello nos va a valer la Query simple que implementamos, pero queremos que, cuando llamemos a la consulta, nos devuelva los BPs y sus entidades relacionadas.
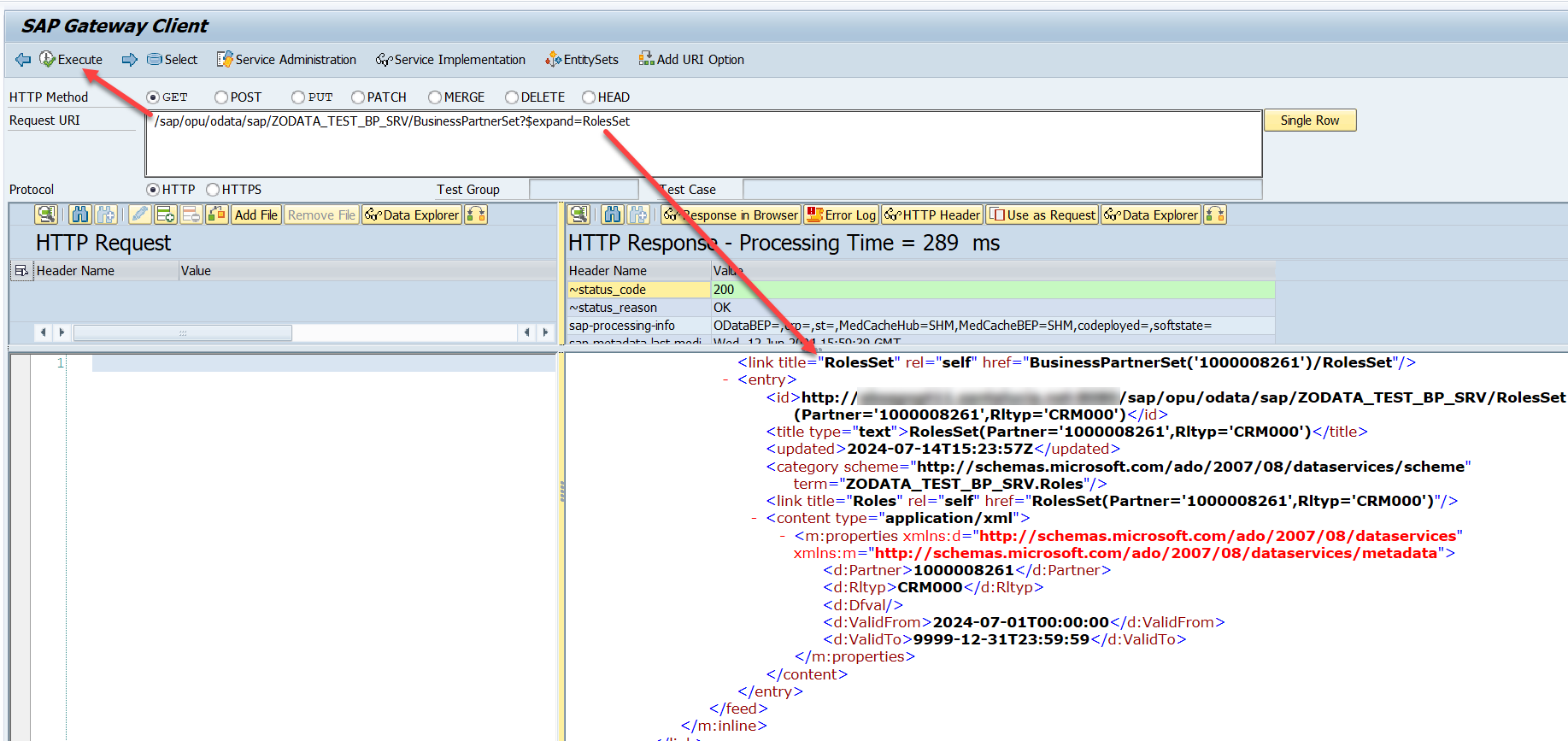
Uso del $expand en la consulta
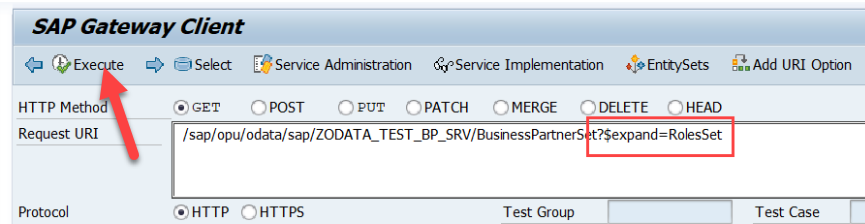
Para poder consultar las subentidades de cada entidad en una consulta, usaremos en la URL de llamada al servicio la sentencia $expand. Podemos ver la documentación oficial OData al respecto de la sentencia $expand. Por ejemplo si hacemos una búsqueda de Business Partners y, para cada uno de ellos queremos saber sus roles, realizaremos la consulta de este modo. Para ello ponemos en el Gateway Client (/IWFND/GW_CLIENT).
Error Method ROLESSET_GET_ENTITYSET not implemented
Pero nos da ese error, y esto es porque no hemos implementado el método del GET_ENTITYSET (dame la colección de datos) de la entidad ROLES.
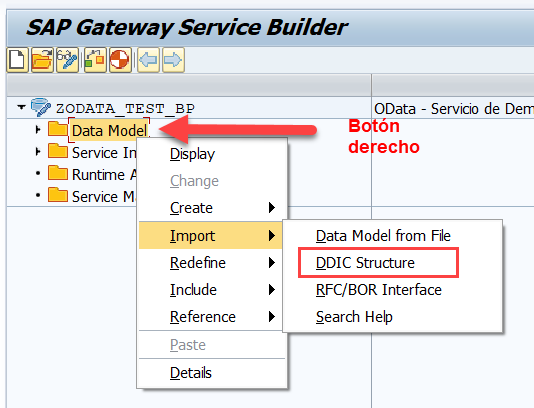
Implementar el GET_ENTITYSET
Para implementar el GET_ENTITYSET nos iremos a nuestra clase Z*DPC_EXT y buscaremos el GET_ENTITYSET de nuestra entidad que queremos consultar. Y redefinimos el método.
Pero claro, una vez redefinido, tenemos que implementar la lógica al respecto de esa acción (GET_ENTITYSET) de esa entidad (ROLES). Vemos que en la firma del método tenemos muchos parámetros de entrada y un par de salida. Son los siguientes:
Parámetros de Entrada
IV_ENTITY_NAME: Nombre de la entidad que se va a manejar en el método. Normalmente, cuando hablamos de métodos propios de una entidad concreta, como es el caso, será irrelevante. Pero en otras ocasiones se trata de métodos genéricos, donde tenemos que cambiar la lógica de la acción propuesta en base a este método.
IV_ENTITY_SET_NAME: Lo mismo que el anterior pero con el EntitySet.
IV_SOURCE_NAME: Nos dirá si partimos de una entidad superior o no y cual es.
IT_FILTER_SELECT_OPTIONS: Tabla con los campos de selección que se hayan usado para la búsqueda del EntitySet mediante la sentencia $filter. En este caso si hemos añadido algún criterio de selección para los Roles. Puedes ver la documentación oficial OData sobre el FILTER.
IS_PAGING: Nos indica el TOP y SKIP para la consulta, esto sirve para acotar el número de resultados y poder paginar. Por ejemplo, si tenemos 1000 registros pero ponemos un TOP de 100 y un SKIP de 500, recuperaremos del 501 al 600. Puedes ver la documentación oficial OData sobre el TOP y SKIP.
IT_KEY_TAB: Si hemos accedido a la entidad por una clave, la suya o la de una entidad superior, en el campo KEY TAB vendrán las claves por las que se accede al EntitySet.
IT_NAVIGATION_PATH: Tabla que contiene la ruta de navegación entre entidades.
IT_ORDER: Tabla con los criterios de ordenación deseados para recuperar los datos de la colección del EntitySet. Puedes ver la documentación oficial OData sobre ORDERBY.
IV_FILTER_STRING: El string de búsqueda con los campos y los valores buscados. Es una forma distinta de manejar los criterios de búsqueda de la tabla IT_FILTER_SELECT_OPTIONS.
IV_SEARCH_STRING: Permite realizar búsquedas de texto completo en los datos de una entidad. Este parámetro permite indicar una cadena de búsqueda que se aplicará a varios campos de la entidad, haciendo más fácil encontrar registros que contengan el texto indicado en cualquier parte de esos campos.
IO_TECH_REQUEST_CONTEXT: Este parámetro proporciona información técnica sobre la solicitud actual. Contiene detalles relevantes del contexto técnico de la llamada al servicio OData, permitiendo acceder a datos importantes para el procesamiento de la solicitud. Desde este parámetro podemos recuperar mucha información:
Usuario llamante
Cabecera HTTP
Parámetros de la URL
IP del cliente
Parámetros de la Query
Parámetros de Salida
ET_ENTITYSET: Tabla de datos de salida de la consulta para devolver el conjunto de entidades (EntitySet) solicitado. Es una tabla interna, con el tipo de datos de la entidada, que contiene los datos que se devuelven al cliente como resultado de la consulta. Por lo tanto, es la tabla resultado que tenemos que rellenar con los datos buscados una vez aplicados los criterios de entrada.
ES_RESPONSE_CONTEXT: Es una estructura de salida de la consulta OData, contiene metadatos sobre la respuesta, como el número de registros devueltos, información de paginación, y cualquier mensaje de error o advertencia.
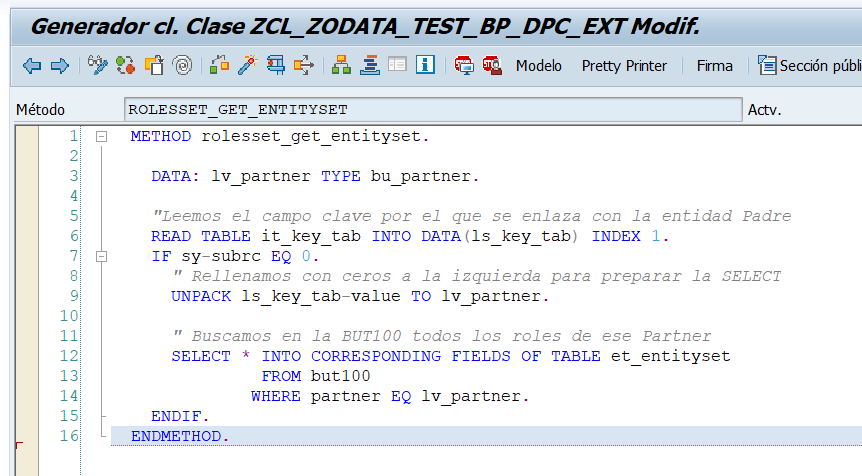
Implementación de ROLESET_GET_ENTITYSET
Bueno, mucha explicación de lo que son todos los parámetros que se manejan en el GET_ENTITYSET pero no mostramos cómo hacerlo en la práctica. Como es imposible abarcarlo todo en un artículo, los ejemplos de implementación serán sencillos, para complicarlo está la definición de los parámetros del GET_ENTITYSET.
Lo primero que vamos a hacer es ver qué nos llega en la entrada cuando usamos un $expand desde la entidad padre. Para ello, lo que queremos es parar la ejecución en ese método, lo que yo hago es poner una sentencia absurda para poder poner un Breakpoint externo.
Si alguna vez se cumple esto sal corriendo
Al ejecutar de nuevo la llamada en el Gateway Client (/IWFND/GW_CLIENT)
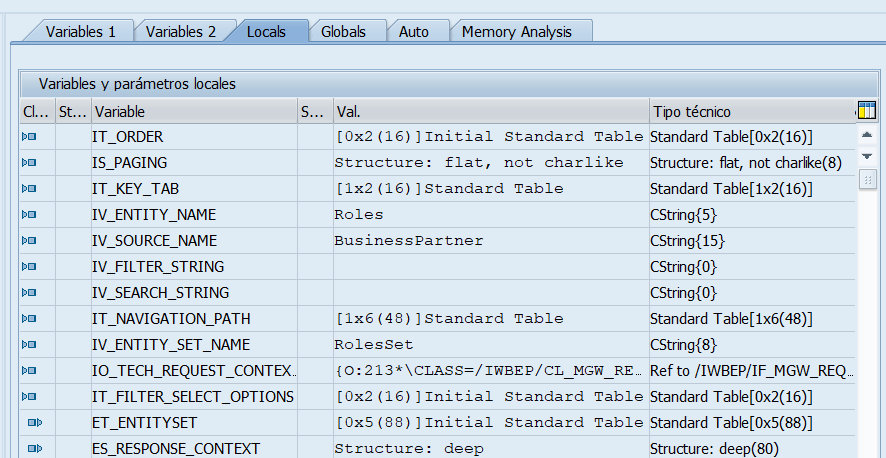
Se abre la sesión debug en el breakpoint externo y podemos ver los datos que nos vienen:
Ahora podemos ver la definición de cada campo que hemos hecho arriba para entenderlo. Vemos que la entidad buscada (IV_ENTITY_NAME) es «Roles» que el origen (IV_SOURCE_NAME) es «BusinessPartner», que no tiene criterios de búsqueda añadidos, ni paginación, ni orden,que la tabla IT_NAVIGATION_PATH tiene un registro con la navigation properties RolesSet desde BusinessPartner, y tiene una clave en la tabla IT_KEY_TAB.
Ahí tenemos nuestro Business Partner padre
Ahora, teniendo el campo Partner en la tabla IT_KEY_TAB vamos a implementar la lógica para rellenar el RolesSet.
Este código se ejecutar una vez por cada Partner servido
Si ahora ejecutamos nuestra sentencia ya veremos datos de los roles de cada uno de los registros de Business Partners.
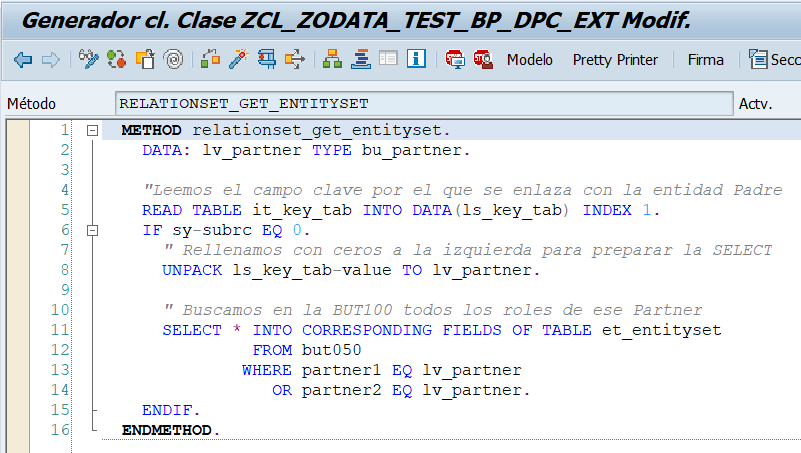
Implementar GET_ENTITYSET del resto de entidades
Una vez tengamos implementado el GET_ENTITYSET de las subentidades nuestra clase Z*DPC_EXT quedará de este modo:
Y para el que le interese los GET_ENTITYSET quedarán de esta forma:
AddressSet
IdentNumbersSet
RelationSet
Seleccionar las entidades a recuperar
Pero claro, tenemos cuatro subentidades subordinadas de BusinessPartner. ¿Cómo tenemos que hacerlo? Para hacerlo pondremos en la sentencia $expand las subentidades que queramos recuperar, separadas por coma. En nuestro ejemplo la sentencia total sería:
El resultado será que, para cada Business Partner, tendremos su colección de Roles, Números de Identificación, Direcciones y Relaciones. Por supuesto, para cada subentidad, tendremos que implementar su GET_ENTITYSET correspondiente.
Lo importante de esto es que podemos elegir qué subentidades recuperar, haciendo la recuperación de datos selectiva y dependiente del llamante.
Nos metemos en harina y dejamos de teorizar. Después del artículo ‘OData y SAP Gateway‘ donde explicamos OData y su uso en SAP. Hoy vamos a aprender lo básico para saber montar un servicio OData en SAP usando el Gateway. Vamos a intentar que esto sea una serie de artículos sobre OData y SAP Gateway.
Serie de Artículos sobre OData
Este artículo pertenece a una serie de artículos que se van complementando poco a poco como itinerario de conocimiento:
Lo primero que vamos a hacer es definir nuestro modelo de datos a extraer. Esto no forma parte del proceso, pero es algo que necesitamos tener claro antes de continuar. Aquí os hago una propuesta. Vamos a hacer un servicio sobre Business Partners (BP) y sus objetos relacionados. Si no sabes lo que es un Business Partner revísa la entrada del blog:
Y además añadimos la estructura sencilla de tablas donde se encuentran estos datos:
Con esta estructura «sencilla» podemos abordar el problema (publicar un servicio web) de múltiples formas. Podríamos crear un servicio de consulta SOAP que por id de BP te devuelva una tabla con tablas anidadas con esa estructura. Pero luego, si queremos crear o actualizar tenemos que crear otro o crear un servicio monstruoso.
La potencia de OData reside en generar estas entidades y subentidades con las acciones CRUD (Create Read Update Delete) que necesitemos sobre cualquier entidad o subentidad. Por lo tanto, con OData hacemos un servicio web de microservicios. Pudiendo elegir entidad por entidad y campo por campo si se puede consultar, crear, actualizar o eliminar.
Estructuras a usar
Para crear este OData podemos hacer que cada entidad del modelo sea una entidad OData. De esta forma veremos que el servicio OData será muy versátil, pudiendo recuperar la profundidad de datos que necesitemos.
Para ello vamos a crear las siguientes estructuras y tipos tabla de las entidades subordinadas a los datos de cabecera.
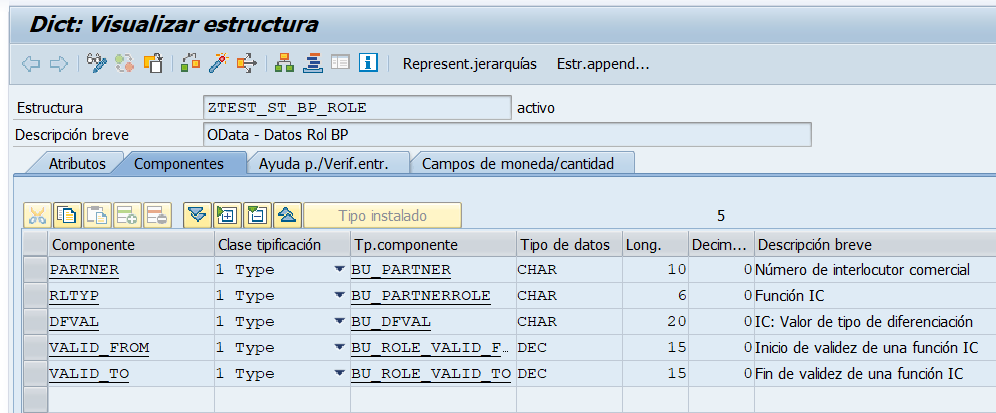
Estructura para Roles de BP
Tipo Tabla para Roles de BP
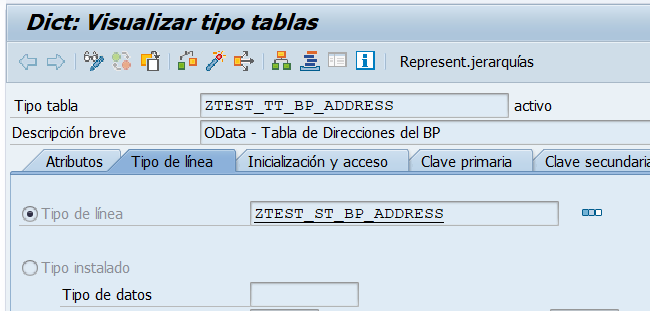
Estructura para Direcciones de BP
Tipo Tabla para Direcciones de BP
Estructura de datos para Relaciones del BP
Tipo Tabla de Relaciones del BP
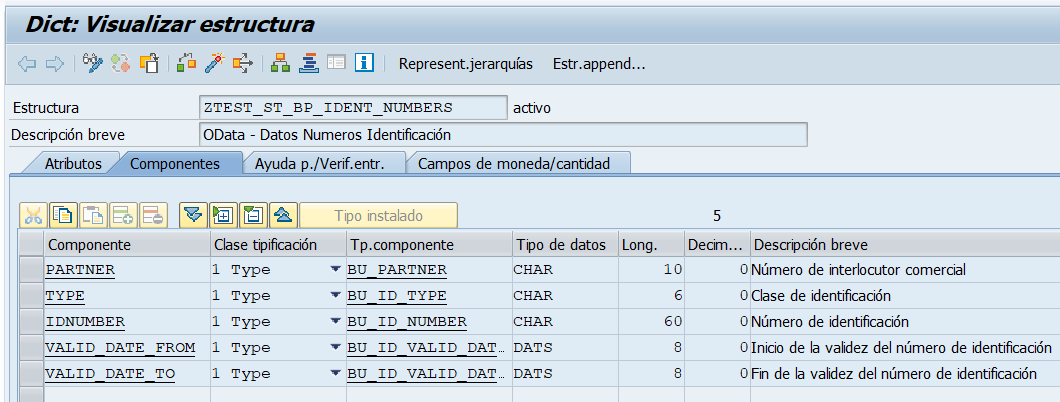
Estructura de Identificadores del BP
Tipo Tabla de Identificadores del BP
Con estos tipos de tablas creamos la estructura de datos de cabecera del BP.
Donde vemos que hay 4 tablas dentro de la estructura para los datos de Roles, Direcciones, Relaciones y Números de identificación del BP.
Gateway Service Builder (SEGW)
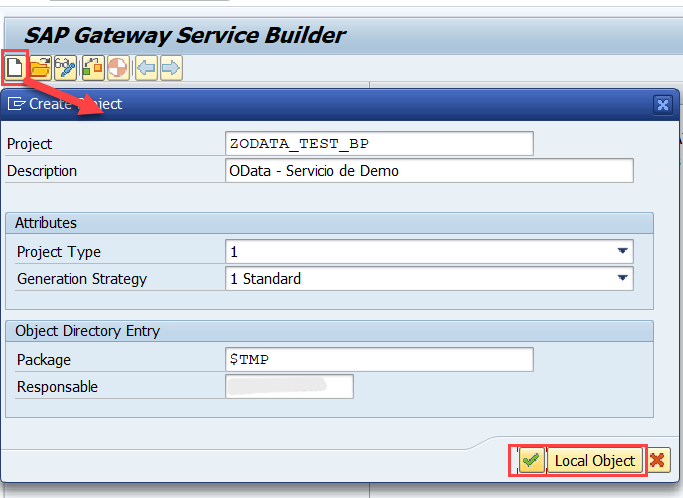
Una vez tenemos nuestro modelo y las estructuras creadas tenemos que crear un proyecto en la Gateway Service Builder (SEGW) y añadir la entidad del BP.
Al pulsar el botón de Nuevo nos aparecerá esta ventana
El campo Project Type es importante, porque nos permitiría crear un servicio OData v4. Ya hablaremos de eso, pero por ahora vamos a hacer un servicio OData básico, ya lo complicaremos más adelante.
Una vez creado el proyecto, estará vacío, por lo que vamos a añadir las entidades. Como previamente hemos creado la entidad de datos generales del Business Partner junto con todas las tablas relacionadas, vamos a importar esa estructura generada.
Entramos en la opción de importar una estructura del diccionario
Añadimos nuestra estructura padre de datos generales de Business Partners.
Seleccionamos nuestra estructura padre
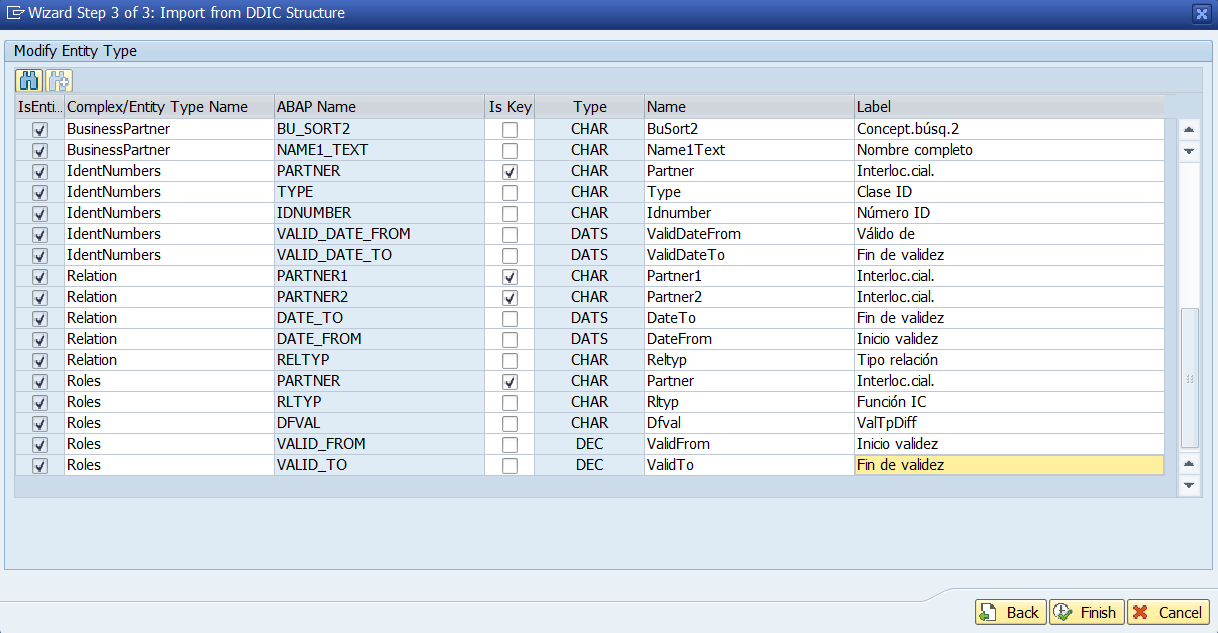
Al darle a Next nos pedirá que indiquemos que campos/entidades queremos importar de la estructura seleccionada.
Como la estructura es nuestra, seleccionamos todo
Una vez hayamos seleccionado los campos y entidades nos pedirá, de cada entidad que vaya a crear y campo, cual es la clave, nombre y etiqueta. No obstante es algo que podemos cambiar posteriormente.
En Address la clave es Partner y Addrnumber
De IdentNumber la clave es PARTNER y TYPE. De Relation la clave es PARTNER1 y PARTNER2. De Roles la clave es PARTNER y RLTYP
Como resultado tendremos cinco entidades creadas:
BusinessPartner
Address
IdentNumbers
Relation
Roles
Cada una de ellas con los atributos y claves seleccionados en el punto anterior.
Relaciones entre Entidades
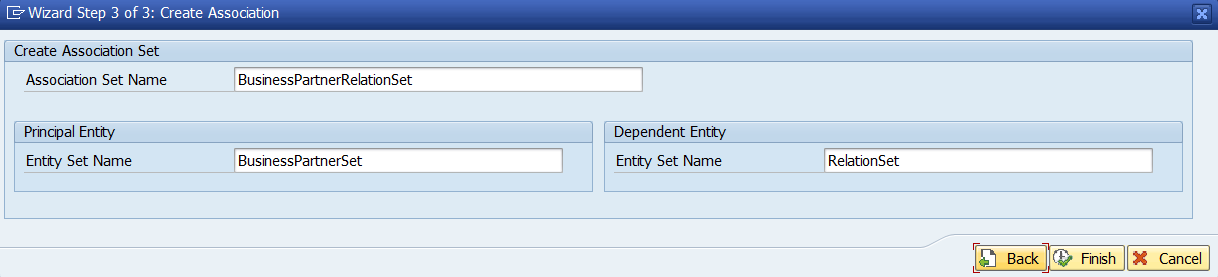
Ahora lo que tenemos que hacer es relacionar las entidades subordinadas con la entidad padre, para ello creamos una Assiciation
Botón derecho en Association y Create
Vamos a ver el ejemplo de Roles, el resto serán iguales puesto que la estructura de entidades es sencilla.
Definición de la Asociación entre entidades y su cardinalidad
Identificamos la asociación de claves entre entidades
Resumen de Asociación
Una vez hayamos hecho todas las asociaciones tendremos que generar el servicio con el botón
Vemos las entidades, asociaciones entre entidades y pulsamos a Generar
Al generar se nos propone unos nombres de clases controladoras del servicio OData. Por norma general esto aceptamos la propuesta y seguimos generando.
Clases controladoras del servicio OData
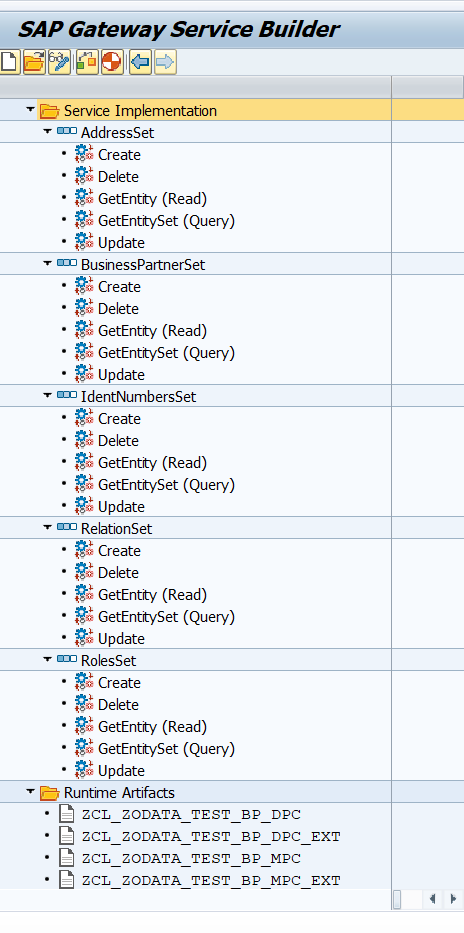
Al generar se nos añade la información de Service Implementation con todas las acciones CRUD de cada una de las entidades.
Implementación del servicio
Una vez tengamos generado el servicio veremos, en la parte de Service Implementation veremos cada una de las acciones posibles de cada una de las entidades. Por cada entidad tendremos las acciones:
Create: Creación de la entidad. Si estamos hablando de BusinessPartner, pues creación de un BP nuevo.
Delete: Borrado de la entidad. Por ejemplo, cuando queremos eliminar una dirección del Business Partner.
GetEntity: Consulta de los datos por clave, es decir, solo consultamos un registro
GetEntitySet: Consulta de los datos por Query, es decir, se va a recuperar una colección (tabla) de datos en base a unos criterios de búsqueda.
Update: Actualización de una entidad ya existente.
Como en nuestro caso se trata de un servicio OData de consulta de datos de BPs nos fijamos en la carpeta de Service Implementation del proyecto OData. Donde vemos cada una de las entidades y subentidades las acciones y, al pulsar doble click vemos el objeto técnico y la clase y el método donde se debe implementar la lógica.
De una entidad vemos sus métodos de implementación de la clase DPC_EXT
La clase donde se debe implementar la lógica es la ZCL_<NOMBRE_PROYECTO>_DPC_EXT (guárdate esto en la cabeza que lo vas a usar mucho). Para acceder a la clase es tan sencillo como entrar en la SE24 o entrar, dando doble-click sobre ella en el apartado Runtime Artifacs.
En una primera instancia veremos todos los métodos del CRUD de cada entidad sin redefinir. Para ir añadiendo nuestro código tenemos que ir redefiniendo cada método en la clase DCP_EXT e ir añadiendo la lógica esto lo haremos con más en otro artículo, pero en este vamos a hacer algo muy básico.
Implementado una query simple de BPs
Para implementar la consulta básica de los Business Partners vamos a implementar el método GET_ENTITYSET de la entidad BusinessPartners. Por lo tanto será el método BUSINESSPARTNERS_GET_ENTITYSET de la clase ZCL_ZODATA_TEXT_BP_DPC_EXT. Para ello debemos redefinir este método.
Formas de Redefinir el método en la clase DPC_EXT
Al redefinir el método aparece una propuesta de código.
Propuesta de código
Vamos a realizar una implementación muy muy sencilla para ver la funcionalidad básica. Todo esto puede llegar a ser mucho más complejo. Ya lo explicaremos.
Ponemos una Select muy sencilla para ver cómo se implementa. En posteriores artículos entraremos en detalle de las posibilidades que nos da de implementación.
Activación del servicio /IWFND/MAINT_SERVICE
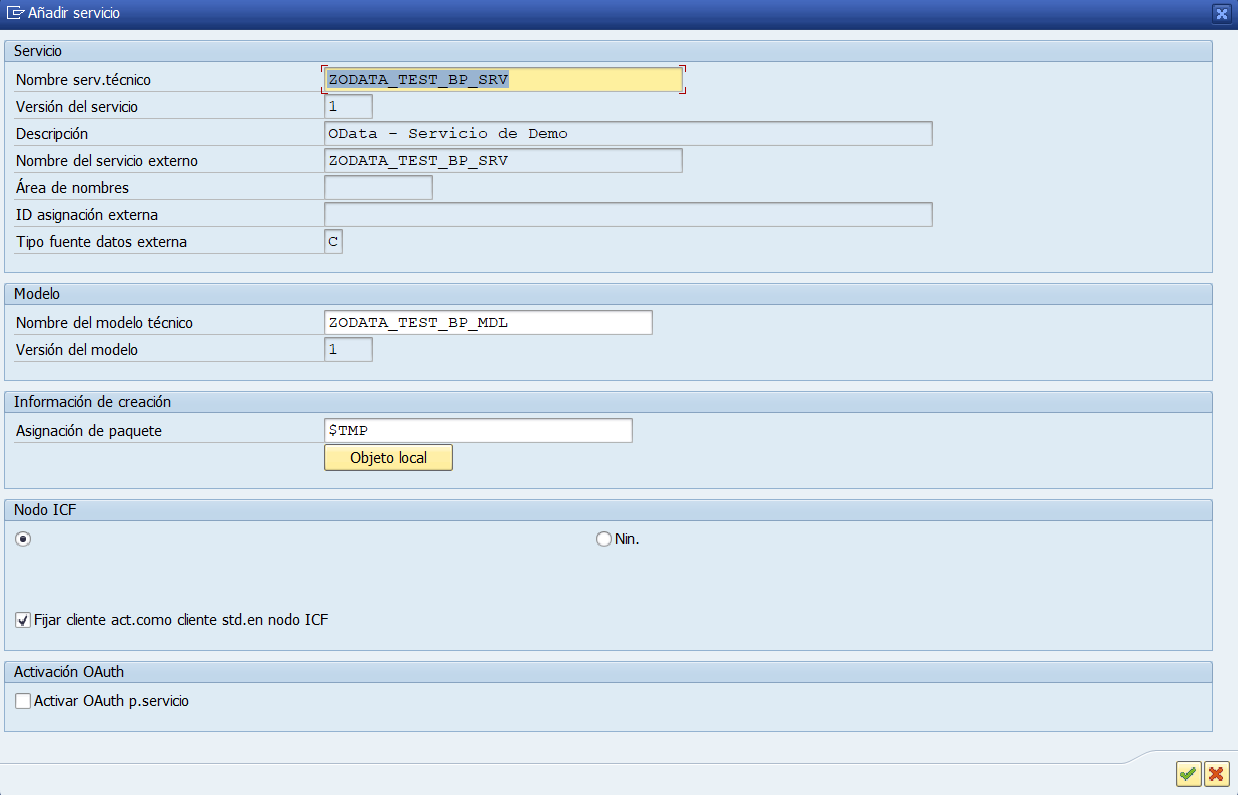
Una vez tenemos el servicio OData generado e implementado tenemos que activar el servicio para que pueda ser llamado, Para ello entramos en la transacción /IWFND/MAINT_SERVICE. Es algo que sólo hay que hacerlo una vez por servicio.
En una primera vez, tenemos que añadir el servicio a la lista.
Al pulsar el botón «Añadir servicio» se nos abrirá una búsqueda de servicios, buscamos el nuestro, lo seleccionamos y pulsamos «Añadir servicios seleccionados».
Añadimos nuestro servicio
Nos pedirá el nombre, paquete y si queremos que se genere el nodo ICF.
Una vez añadido el servicio lo tendremos disponible en la lista de servicios de la /IWFND/MAINT_SERVICE.
Probando el servicio
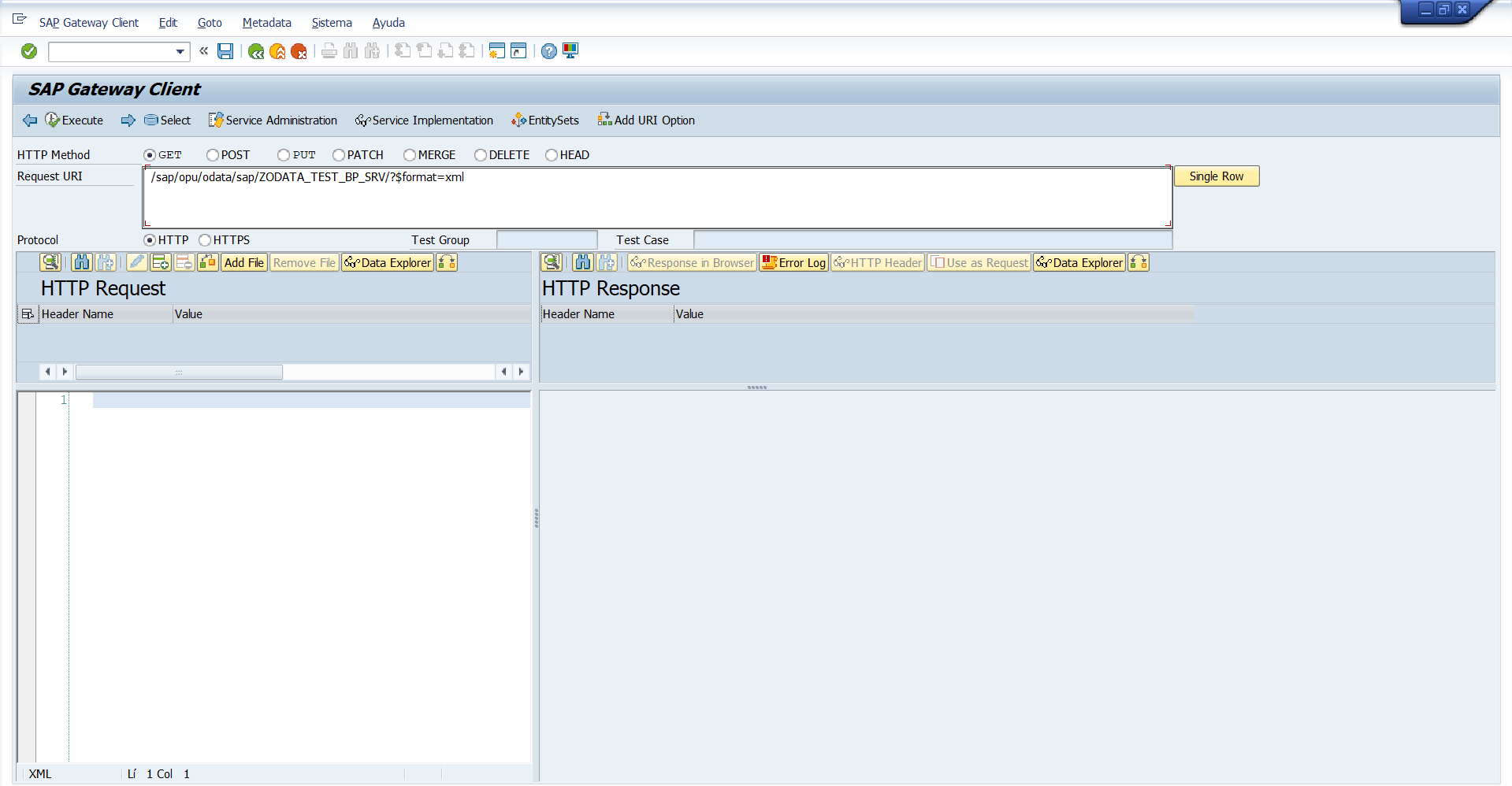
Una vez tengamos el servicio activo en la /IWFND/MAINT_SERVICE podemos entrar en el SAP Gateway Client para probar el servicio OData. Para ello podemos entrar con la transacción /IWFND/GW_CLIENT o bien desde la /IWFND/MAINT_SERVICE pulsando el botón Cliente SAP Gateway.
Podemos pulsar este botón o ir directamente a la Transacción /IWFND/GW_CLIENT
Una vez dentro del SAP Gateway Client veremos la siguiente pantalla. Pero esa URL propuesta lo único que nos dará será un XML de definición del servicio. Si queremos probarlo será en base a una entidad con las acciones CRUD.
Una ves aquí podemos seleccionar la entidad sobre la que queramos hacer la acción con el botón .
Seleccionamos BusinessPartnerSet porque es lo que hemos configurado
Resumen
El resultado de este servicio OData que hemos creado es una consulta básica a los datos de cabecera de los Business Partners. Tan básica que no tiene ni filtros y no sacamos datos de subentidades. Pero el objetivo es que tuviésemos algo que pueda ejecutarse de forma fácil para ver un resultado. En siguientes capítulos de esta serie me gustaría abordar:
Subentidades de una entidad (Expanded Entities)
Filtros en la consulta
Opciones de CRUD por entidad en OData
Documentar un servicio OData con OpenAPI/Swagger
Probar el servicio con Postman
Creación de un OData desde un Módulo de Función
Veremos a lo que llegamos, porque esto tiene mucho contenido, paso a paso.
Vamos a entrar en la harina de SAP Build, hemos ido preparando el terreno con los artículos Low-Code / No-Code y SAP BTP – Business Technology Platform (el que no los haya leído es una buena base para esto que vamos a contar). Ahora toca entrar en la suite de Low-Code/No-Code y RPA de SAP, SAP Build.
De cara a entender bien este artículo os recomiendo la realización de los cursos (gratuitos):
Como comenté en el artículo de Low-Code / No-Code, SAP compró la empresa AppGyver para potenciar la parte de Low-Code y automatización, de ahí SAP creó SAP Build Apps. Además está cimentado sobre SAP BTP como framework de trabajo. Pero SAP Build no es sólo eso, tiene tres áreas fundamentales, cada una especializada en un propósito:
SAP Build Apps
Inicialmente llamado AppGyver, con SAP Build Apps podemos realizar, arrastrando cajitas, aplicaciones web o de movilidad sin necesidad de tirar ningún código. Un ejemplo sacado de la cuenta oficial de SAP:
¿Podrías ir más rápido por favor?
A ver, va a toda máquina y nos perdemos un poco, pero el concepto es que, sin necesidad de desarrollar código es capaz de hacer una aplicación. Contamos con un área de trabajo con zonas bien diferenciadas:
No voy a explicarlo todo, que para eso está el curso que es ameno y fácil. Pero básicamente tenemos:
Canvas: El lienzo propiamente dicho, donde se van a poner los componentes visuales.
Listado de componentes: Donde poder usar botones, campos de texto, labels, checkbox, imágenes, etc. Sólo con arrastrar y soltar en tu lienzo ya lo tienes.
Propiedades: Para cambiar las propiedades de los componentes. Nombre, texto, etc…
Logic Pane: Muy importante. Abajo a la derecha hay un enlace «Add logic to…» para darle lógica a los botones, campos, etc. Solo tenemos que seleccionarlo y darle la lógica que queramos.
Data: Arriba tenemos otro botón importante, este para especificar una BBDD o bien una definir la llamada a un servicio REST.
Launch: Para probar nuestra App.
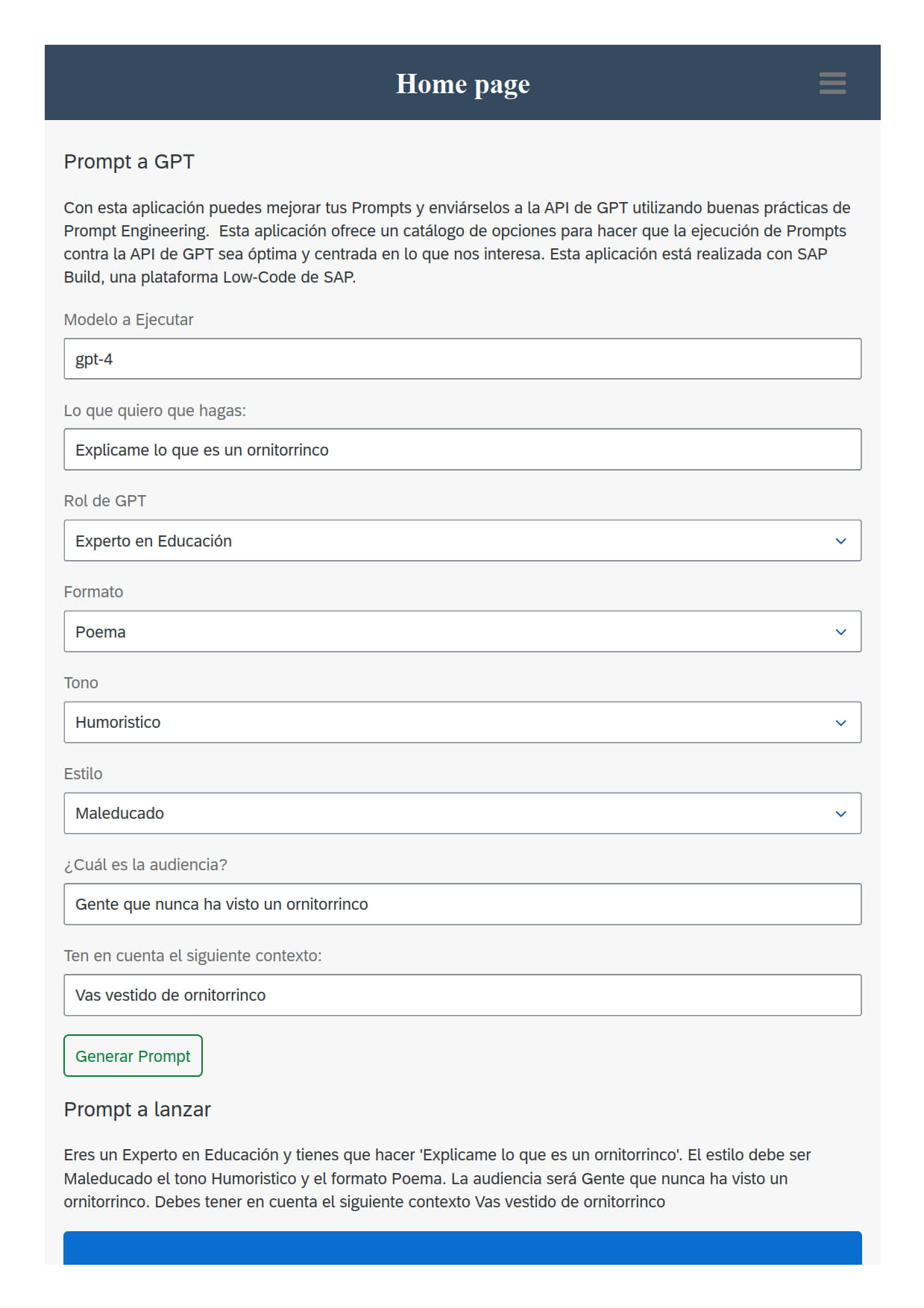
Ejemplo de una App creada por mi en Sap Build que genera un prompt para GPT, lo lanza contra la API y muestra el resultado (ya lo explicaré)
El resultado es una app móvil o web de este tipo:
Y con resultado de GPT
No es Gustavo Adolfo Bécquer
En otro artículo desgranaré cómo he creado esta aplicación en el SAP Build de pruebas que proporciona SAP.
SAP Build Process Automation
La aplicación SAP Build Process Automation combina gestión de Workflows y RPA (Robotic Process Automation) con herramientas visuales para hacer procesos sin necesidad de programar. Se apoya en la Inteligencia Artificial para adaptarse y saber leer el contenido de facturas, pedidos u otros documentos.
Con SAP Build Process Automation se puede hacer:
Crear Workflows con el inicio en un formulario o en el escaneo de un documento. Dichos workflows pueden contener formularios de aprobación, ramas condicionales, automatizaciones (RPA), iniciar otros workflows o usar contenido preconfigurado (como las librerías de Python)
Crear robots (RPA) para la realización de tareas repetitivas o tediosas, como extraer datos de documentos para pasarlos a nuestro sistema, o enviar emails automáticos. Todo esto pudiendo apoyarse en la Inteligencia Artificial para reconocer datos de las facturas y documentos. Se pueden crear robots como «cajas negras» de funcionalidad para ser llamadas en otros procesos como si fuesen una API (librerías).
Usar las automatizaciones ya preconfiguradas en la herramienta en nuestras propias automatizaciones.
SAP Build Process Automation contiene un Dashboard para monitorizar todos los workflows y automatizaciones.
Para ver ejemplos podemos pasarnos por el canal de youtube SAP Build Process Automation donde podemos ver videos demostrativos tan interesantes como este, que toma un documento y saca los datos de factura y comienza un proceso de aprobación.
A esto se le puede añadir Inteligencia Artificial para que, en vez de tener que tener una plantilla de campos, sepa identificarlos «viendo» el documento.
SAP Build Work Zone
Y por último, pero para nada menos importante. Tenemos el SAP Build Work Zone que es una plataforma donde los usuarios y administradores pueden crearse sus propios sitios web usando múltiples herramientas y tomando información tanto de aplicaciones SAP como externas.
Es complicado de entender y el papel lo soporta todo. Pero imaginaos que tenemos una herramienta donde poder crearnos nuestros sitios web con el resumen de todo lo que necesitamos en nuestro día a día, tanto interno de SAP como externo. Una especie de Cuadro de mando. Además de esto los administradores también pueden crear espacios de trabajo colaborativos, con foros, feeds, base de datos de conocimiento, etc… Y más aún, puedes compartir tus sitios creados o entrar en sitios creados por tus compañeros o los administradores.
¡¡Vaya!! ¿Dónde puedo comprar esto?
Todo esto, por supuesto, con tecnología Low-Code/No-Code. Usando el ratón y arrastrando y soltando. ¿Te lo crees? Pues yo a medias… 😅 Una cosa es poder crear páginas con datos y otra es ver cómo conectar las fuentes de datos a esos datos.
Versiones de SAP Build Work Zone
Hay dos versiones disponibles en el mercado las cuales no tienen nada que ver entre sí (cosas de SAP).
Standard Edition: Realmente es el antiguo Launchpad Service. SAP lo renonombró supongo que por temas de marketing, pero no tiene nada que ver con SAP Work Zone Advanced. Se trata de un servicio a activar en SAP BTP para ser usado y es tecnología SAPUI5.
Advanced Edition: Es el Work Zone que se presenta en los videos, imágenes y presentaciones. No tenemos acceso a probarlo porque lo que te deja SAP es probarlo en un sistema Trial de BTP y eso solo te permite activar el servicio de SAP Build Work Zone Standard Edition. Podeis ver más información al respecto en el Help de SAP. Si veo que hay interés quizás haga una entrada sobre esta parte que es la más «oscura» del ecosistema SAP Build.
Builders Beyond Code
El pasado 5 de Septiembre de 2023 hubo un evento en vivo en LinkedIn de SAP sobre SAP Build donde se habla de SAP Build y se muestran ejemplos y funcionalidades,.
En este evento se muestran ejemplos de todas las herramientas de la suite SAP Build. En concreto es muy interesante la parte en la cual Daniel Wroblewski muestra la funcionalidad en vivo (a partir del minuto 43). Donde muestra funcionalidades tan interesantes como:
SAP Build Apps (minuto 1:03): Crea una aplicación en 5 minutos que se conecta con un S/4 y muestra una lista de BPs.
SAP Build Process Automation (minuto 1:08): Cada vez que alguien cree un BPs de tipo individual en el sistema S/4 que se quiera relacionar con otro BP de tipo organización se lanzará un workflow de aprobación para que alguien apruebe esa creación. Pero en este caso no explica cómo ha hecho el RPA, simplemente muestra el resultado. Mal por Daniel.
SAP Build Process Automation (minuto 1:13): Usa la web www.rpachallence.com para demostrar que con RPA se pueden tomar datos de un excel, pasar cada campo a un campo del formulario y darle al botón.
SAP Build Process Automation (minuto 1:15): Copia un Proyecto del Store de SAP Build que envía mails vía outlook. Vamos que descubre el fuego. Realiza el envío de email vía un formulario externo, pero no le funciona (cosas del directo). El objetivo de esta demo era demostrar que, partiendo de un documento, word, pdf o excel de un evento con participantes, usando RPA puedes automatizar el envío emails de certificados de participación a todos los participantes.
No realiza ninguna demo de SAP Build Work Zone. 😥, supongo que por el mismo motivo por el cual no tenemos acceso a un SAP Build Work Zone de Trial. El resto de la charla es una ronda de preguntas acerca de procesos de negocio.
Mi Opinión
Creo que esto es otra tendencia a nivel de software empresarial. Las empresas de software tienen claro que democratizar el desarrollo les hace imprescindibles y se «controla» el desarrollo a medida sin control. Además es algo que se vende muy bien a los CIOs y CEOs de las empresas.
No obstante, creo que le queda mucho a todo esto para que sea una realidad palpable. La gente, con suerte, sabe pedir sus requerimientos a nivel tecnológico, como para saber implementarlos. El negocio va a seguir necesitando, y mucho, a consultores que traduzcan entre lenguajes. Y al final da igual que el consultor tenga que desarrollar 10.000 líneas de código en 3 meses, que tenga que hacer una app Low-Code/No-Code en 3 meses.